type
status
date
slug
summary
tags
category
icon
password
GraphQL 是什么
GraphQL规范早在2012年[1]已在Facebook的移动端开始使用并在2015年开源,没错,与其说是一种查询语言不如说是一种规范,其嵌入到各种语言中使用,不同语言的实现和使用或多或少都有些许不多,所以觉得说是规范更为合适。
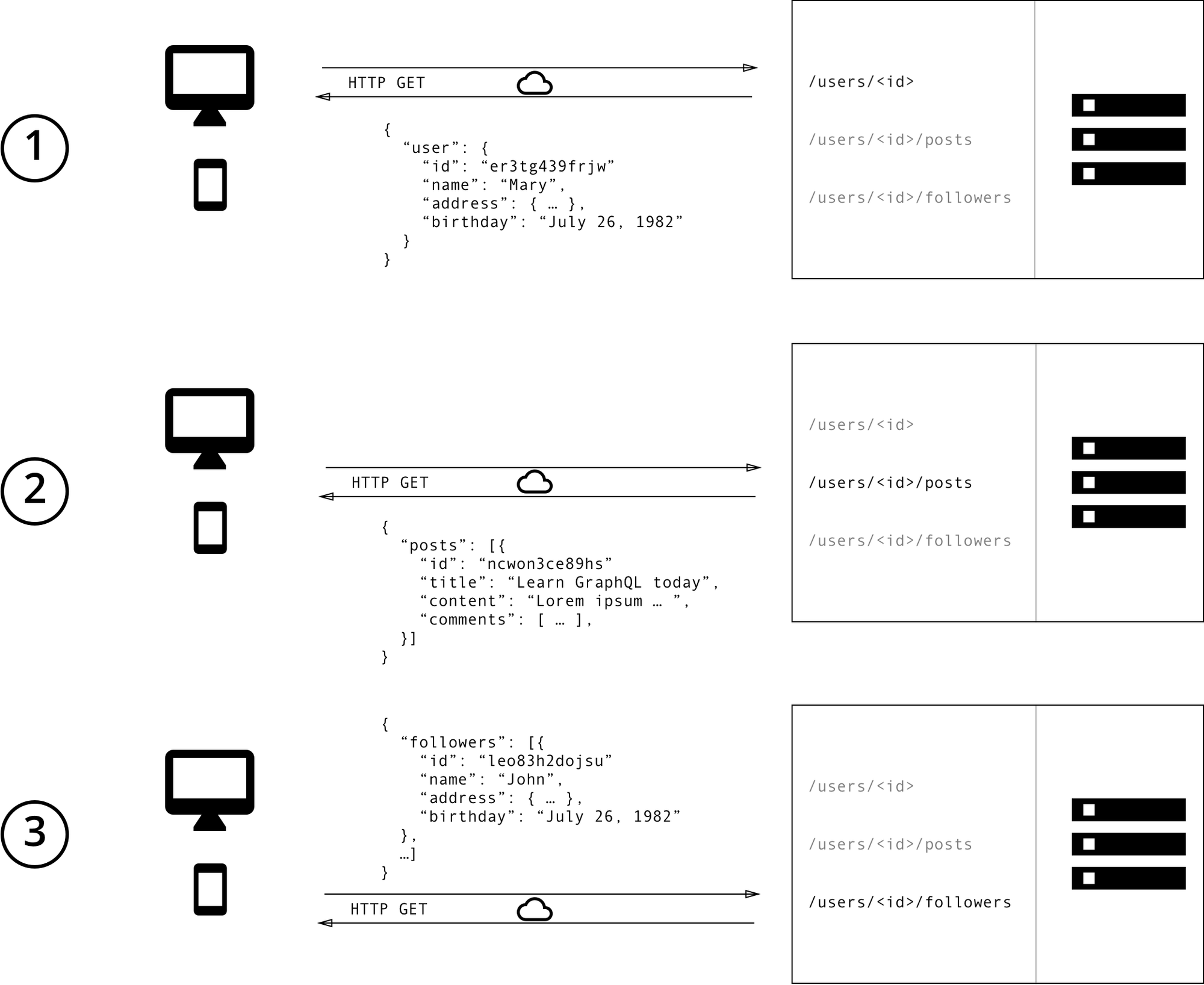
先来看一种场景,在Facebook中搜索Biden这个用户,点击进去加载主要由3部分组成:姓名头像简介粉丝、发表的内容、各个Posts的点赞评论和评论内容。我们从搜索处点击某个用户即传入的是userId,按照一般Restful API获取数据方式为:根据userId获取姓名简介头像等个人信息,然后在获取该userId下最近发表的内容id,根据每个内容id在获取内容点赞评论信息,一般涉及多个 API 请求接口
https://www.howtographql.com/basics/1-graphql-is-the-better-rest/
如果是GraphQL,因数据经过图数据结构抽象,只需访问一次接口,即可把想要的数据查询出来
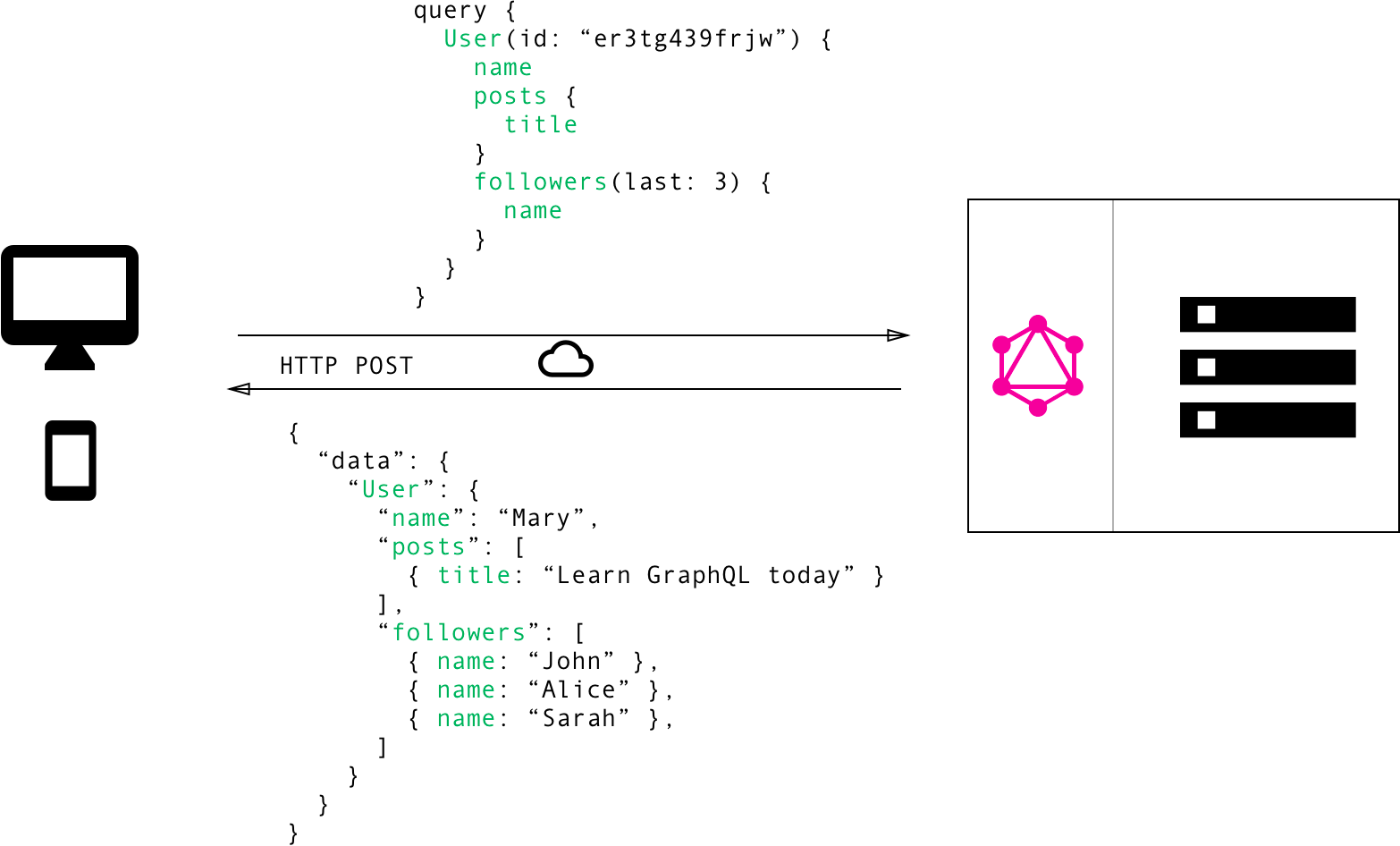
这里性能上的优势就可以体现出来了。
虽然Restful API也可以做一个接口,根据传入的userId把要查的数据查出来,不过当有其他业务场景需要在这基础上增加返回字段时,那就又需要增加一个接口,加上现在一般是前后端分离架构,后端的修改往往需要与前端协调,这里的每更改一个点涉及的沟通成本、改动引发成本在项目达到一定规模后需要一定的工作量。
如果前端能够以一种查询方式,不依赖于具体的后端API接口,首先前端不用看后端API接口文档,沟通量也会降低。而且刚刚上述加载视频评论的场景,对于API获取的数据无需在前端做很大的处理,
所查即所得,那么在加载性能上,也会有很大的改善~于是乎,GraphQL 产生了,它是在数据存储时以把数据转换为图的形式,然后在查的时候就更高效了,还有就是前端在获取数据,调API的时,因为后端的API不是死的,他能以他想获取他仅想要具体的表具体字段,不同表不同字段的数据,查过来也不需要做什么处理,就可以用了。相当于,前端在调API接口的时候,就可以指定具体的数据表和字段,非常方便~
GraphQL 安全性问题
相信这时候大家应该也知道,由于GraphQL更多是偏向于前端查询,在配置或编写不当的时候,经常容易出现全局越权或者未授权的情况发生。
当然也还有其他安全问题,跟进靶场看看先~

插一句,如果没学过GraphQL可以花1小时多丢时间跟着学学写写 https://www.youtube.com/watch?v=ZQL7tL2S0oQ ,不过里面没有提及修改和删除操作,可以尝试自己写一下,熟练一下GraphQL的编写,最后可对比一下靶场中 Python 的写法,这样食用更佳~
指纹识别
https://github.com/dolevf/graphw00f
找 graphql 路径
识别具体指纹
结果
拒绝服务 - 未限制批处理
GraphQL 支持批量查询请求,先简单了解一下
Graphene,nodejs 使用的 apollo 类似,不过 Graphene 是先 core/views.py 注册路由,定义 scheme,对应的 query 有第一关提示为请求
systemUpdate 查询Graphene 的对应解析为 systemUpdate -> resolve_system_update 即最终调用 resolve_system_update 方法,该方法调用 security.simulate_load 这里题目假设这个为高IO处理,所以使用了 sleep 来进行模拟,我们可以适当把 loads 改为
[20, 30, 40, 50] ,重启一下服务。这样单个请求看起来正常点,2-5秒左右。
然后普通的 query 是在单个花括号的,由于 graphql 支持批处理,可以通过列表包含各个请求,然后 graphql 同时去处理,如果都是些高IO花销请求,那就可以造成DOS了,如
原先一个只在 2-5秒,这时返回时间变成 25s 左右
防御方法:
高 IO schema,限制单次传入次数
一些参考



拒绝服务 - 深度递归查询
在GraphQL中,查询时如果指定的两个类型存在相互引用,那么查询我们去查时就可以无限套娃最终导致指数爆炸
通过查看代码的数据模型,发现 Owner 和 Paste 存在相互引用
尝试套娃
报错
找了一下代码,好像没
PasteObjectConnection 这种东西,看了下wp发现要加上 edge 和 node,
搜了下这两个字段的含义,原来graphql为了处理分页和mutate时做了一种叫 relay 的机制。仔细看我们刚刚到报错提及
Connection ,一个 connection 由对象组成,但我们代码里好像没定义这个东西在看了一下 graphene 文档,发现类中定义了
graphene.relay.Node 即会启用 relay 分页机制关于 relay 分页机制进一步讲解可以参考:

也就是说,当
pastes 查询访问 paste 类型的 owner 类型时,查询的是 PasteObject 里的 owner ,里面的数据是可以访问的,此时 paste 和 owner 为一个 coneection ,而当进一步查询 owner 类型的 paste 类型时,此时变成查 PasteObjectConnection 的 owner 字段,相当于跨 connection 查询,而 PasteObjectConnection 并没有 owner 这个字段,所以就报错了。所以跨 connection 查应该是先查 connection 边连着的 node,就是 owner 里 paste 的 id 了,也就是变成
返回结果正常
现在我们的套的层数要足够多,才能让 CPU 飙高,甚至打崩 graphql 服务,这里套了50多层,返回连接超时,但CPU占用不高,也没打崩,(nodejs 可以,不知为啥这里不行了…)
拒绝服务 - 资源密集型
其实就请求不同的查询接口,看看哪个返回时间更久,然后在去请求时间花销更长的
拒绝服务 - 重复字段填充
garphql 一般的查询时不会禁用重复字段,即可以填充无限个相同字段,让服务端去处理
但本机测试,除了延迟,和刚请求那会会有小小波动,好像没啥影响…,不过能检测禁用掉这种请求方式肯定最好,因为这里塞的更多,最终也只会返回一个字段
拒绝服务 - 重命名 bypass
假如说服务端有对批处理进行限制,但未获取其重命名的在进行限制的话,可通过重命名的方式进行 bypass,这里就算是 expert 模式,也可以通过这个进行 bypass
这里注意
: 符号要贴着 systemUpdate ,因为靶场在中间件中的获取请求字段的方式为,他根据是否为纯数字字母来进行判断。然后在 graphql 的处理中,是可以正常进行解析的。
信息泄漏 - 开启缺省模式
缺省查询可以通过指定
__schema 来查询目前所支持的查询方式和查询名称比如查询 query 不一定叫做
Query ,修改操作不一定叫做 Mutation,比如在这里,修改操作就叫做 Mutations,所以一般先查 __schema, 然后就可以查看所有数据类型和接口查询方式了具体某种类型可以通过修改为
__type (name: "PasteObject") 即可查询 PasteObject 的数据结构,这样还不足以查看 mutation 的访问和 subscription 的访问,可以像下面这样可参考下链接参考各种语言禁用缺省查询

信息泄漏 - 开发环境
直接访问 http://tari.local:5000/graphiql ,因为 graphql 有一个集成等开发环境,方便调试用的
信息泄漏 - 字段提示
当我们输入错误的 field 字段时,graphql 会提示与这个字段相似的字段名称
输入
输出
可见回显了 system 相关的一些接口
利用工具:

信息泄漏 - SSRF
importPaste mutation 用到了 curl 探测主机存活主要是熟悉下 mutation 的请求方式
注入类 - 命令 & XSS & HTML注入
第1个命令注入:
importPaste mutation 直接使用命令拼接同 ssrf 熟悉下 mutation 的请求方式
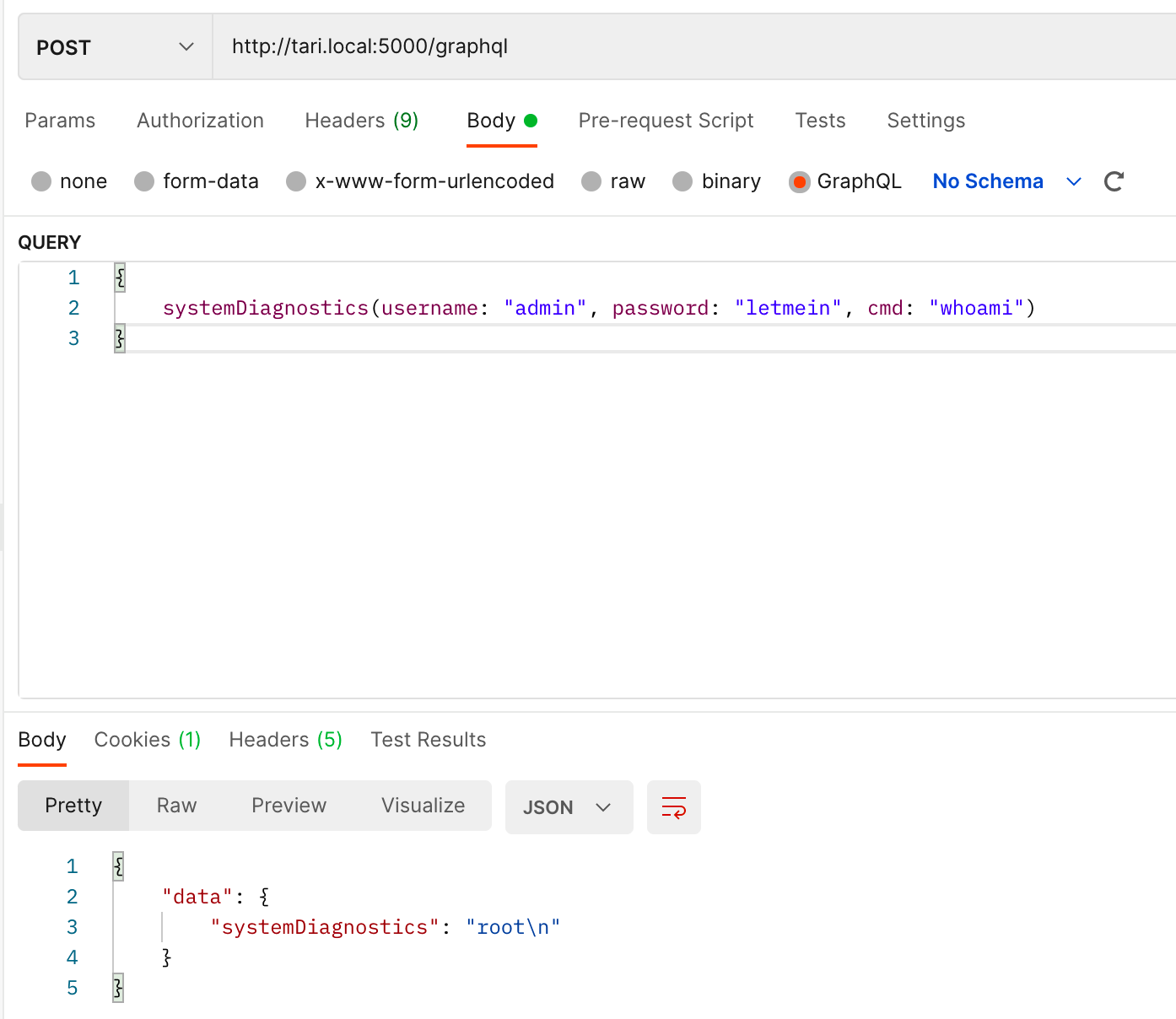
第2个命令注入:postman写好挂个上游代理到burp爆破出密码(或者 graphiql 写好burp抓包均可),然后传入cmd命令执行即可
这里注意每次启动,password 都会从下面几个中随机选一个
XSS:在页面 Create Paste 插入XSS代码即可
HTML 注入,与XSS一样,即注入 HTML 代码
注入类 - 日志欺骗
日志记录通过
Audit.create_audit_entry(gqloperation=helpers.get_opname(info.operation)) 记录日志,断点跟进 helpers.get_opname 方法,可知最终获取到的为操作名称,如果获取不到,则记录为 "No Operation"。比如记录为
pwned
CreatePaste 通过抓包可以发现请求包为 mutation CreatePaste (.... 直接改包会发现请求解析有问题或者日志篡改不了。通过自己构造请求则可以把日志篡改为
nonoPaste
Emmm,其实专家模式也有点问题,虽然指定了白名单,但
这样子还是记录错日志了啊(
认证绕过 - graphiql 界面保护 bypass
在 信息泄漏 - 开发环境 ,其实虽然 graphiql 页面可以访问,但其实是用不了的,如上代码段,保护方式为获取Cookie env字段是否为
graphiql:enable查询黑名单 bypass
这一关需要修改一下 core/views.py 文件,注释 OpNameProtectionMiddleware 中间件
因
on_denylist 方法通过分割空白字符后拼接在判断查询是否在黑名单内当然查询为
就会变成
querygood{systemHealth} 进而避开黑名单杂项 - 目录穿越
普通目录穿越
总结
除了配置不当、越权或未授权,这个靶场没咋提及,tari感觉拒绝服务相对来说在GraphQL中算是比较有特色些的问题了
当然除了靶场中涉及的,还有像GraphQL注入、CSRF也是不错的姿势,不过靶场没涉及,有兴趣的通过可以戳

tari也是刚接触GraphQL不久,欢迎交流~