 Linux命名空间机制及其隔离不当导致的漏洞
Linux命名空间机制及其隔离不当导致的漏洞type
status
date
slug
summary
tags
category
icon
password
历史
Linux命名空间灵感源自Unix系统命名空间功能,从2002年2.4.19内核版本开始集成至Linux中,Linux内核3.8中引入用户命名空间提供了足够容器支持功能,并逐步发展至今,
命令空间类型
Linux 内核经过迭代版本变更共提供 8 种命名空间(表1)
类型 | 功能说明 | 内核 |
Mount (mnt) | 挂载点和文件系统隔离 | 2.4.19[2] |
UTS | 主机名隔离 | 2.6.19[3] |
Interprocess Communication (ipc) | 进程间通信隔离 | 2.6.19[4] |
Process ID (pid) | 进程隔离 | 2.6.24[5] |
Network (net) | 网络隔离 | 2.6.29[6] |
User ID (user) | 用户隔离 | 3.8[7] |
Control group (cgroup) | 系统资源使用隔离 | 4.6[8] |
Time Namespace | 系统时间隔离 | 5.6[9] |
- 进程命名空间是嵌套的,即当一个进程被创建时,从其当前命名空间到其初始化命名空间,每个命名空间都有一个pid,而且有个规律:子进程的pid比父进程的小。
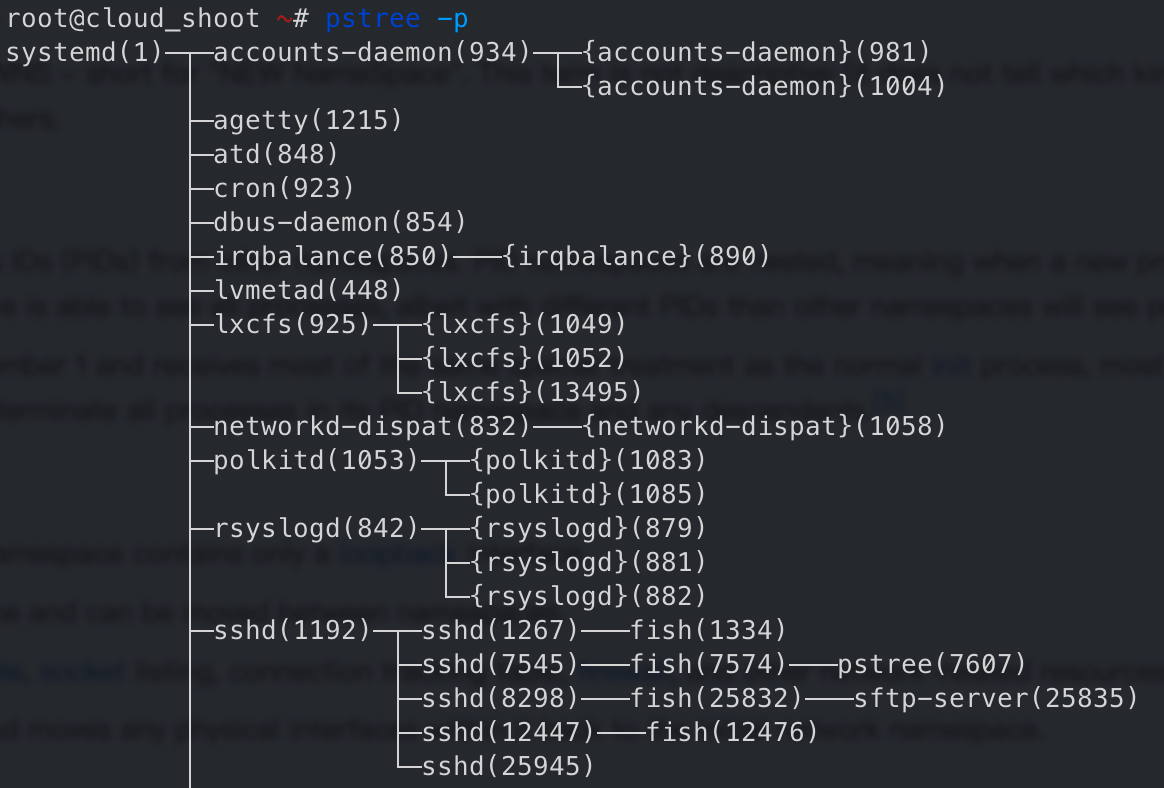
- pid 还有一个比较有意思的知识,Linux 系统中 pid 为 1 是系统启动后创建的第1个进程,或者叫 init process,它有一个特征是 orphaned processes 孤立进程附加到这上面,也就是说,如果 pid 1 被 kill 后,他立刻会终结附加到其上的所有子进程,不过默认 pid 1 是被保护起来的,无法正常通过
kill -9 1等 kill 操作杀死,以保证操作系统的稳定运行,不过可以通过 gdb[10] 来干掉:gdb -p 1后执行kill
- pid 这里有一个大家可能已用过的案例,即WSL无法使用systemctl的解决方案,因为WSL初始PID不是1,所以用不了,通过把自己隔离让自己看到自己的PID为1
- User ID (user) 提供的用户隔离正是容器化的开始,因为他可以摒弃传统的用户权限分级和控制手段。比如一个命名空间内,可以让其认为自己是 root (uid=0),但实际上 uid是1400000,用户命名空间也是嵌套的
- Control group (cgroup) 比如限制某个容器能使用几个CPU,多少内存的特性就是因为这个命名空间
- 其中 Network 和 User 在Linux 2.6.24 和 2.6.23 已有,到表中记录版本才完善
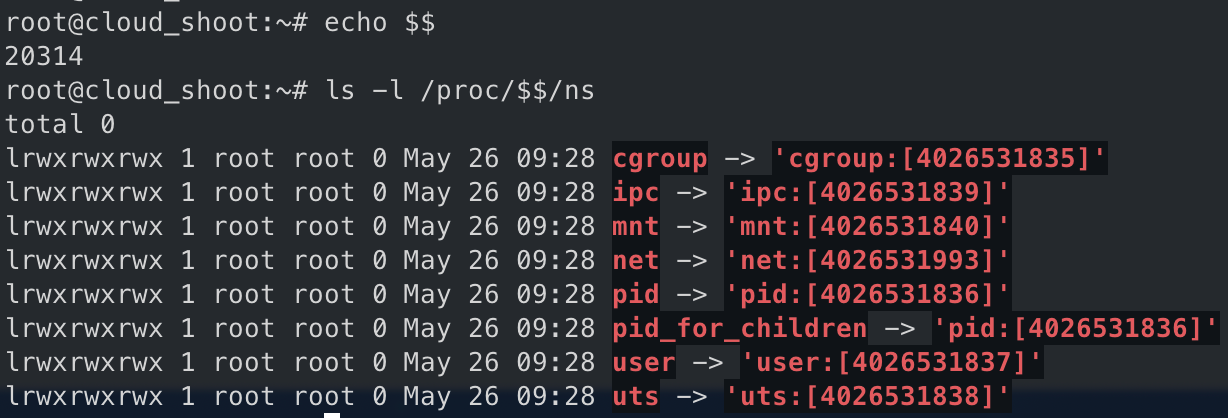
确认当前 bash进程的PID 和 各个namespace,中括号内为 namespace 编号
实现命名空间主要是3个系统调用
- clone() 实现线程的系统调用,用来创建一个新的进程,并可以通过设置命名空间类型参数达到隔离。
unshare()使某进程脱离某个namespace
setns()把某进程加入到某个namespace
mnt隔离[11]
没有隔离的mount
为了简单起见使用tmpfs这种基于内存的文件系统来模拟
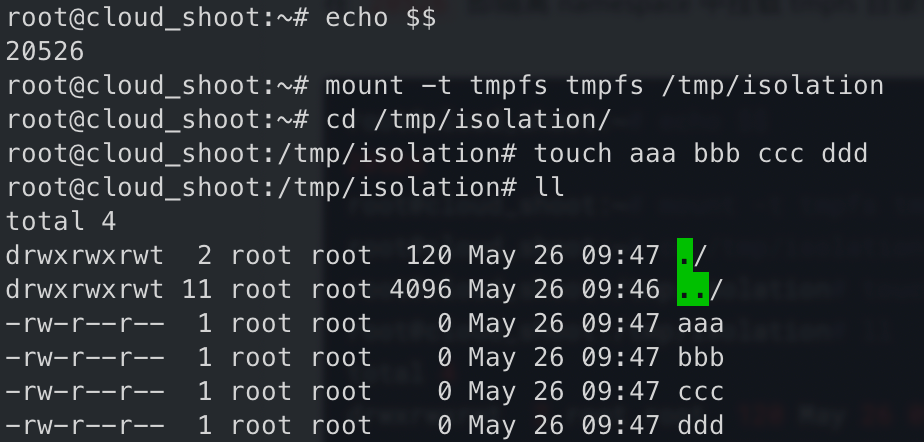
新起一个 bash,文件存在
有隔离的 mount
先创建个测试目录
Linux内核也提供系统函数实现[12],这里直接使用Linux unshare命令实现隔离
使用
unshare 隔离 mnt namespace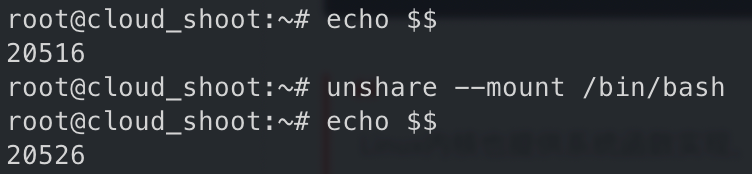
可以清楚看到两个进程为父子进程关系.
20516
在
20526 即隔离 namespace 中挂载 tmpfs 目录和文件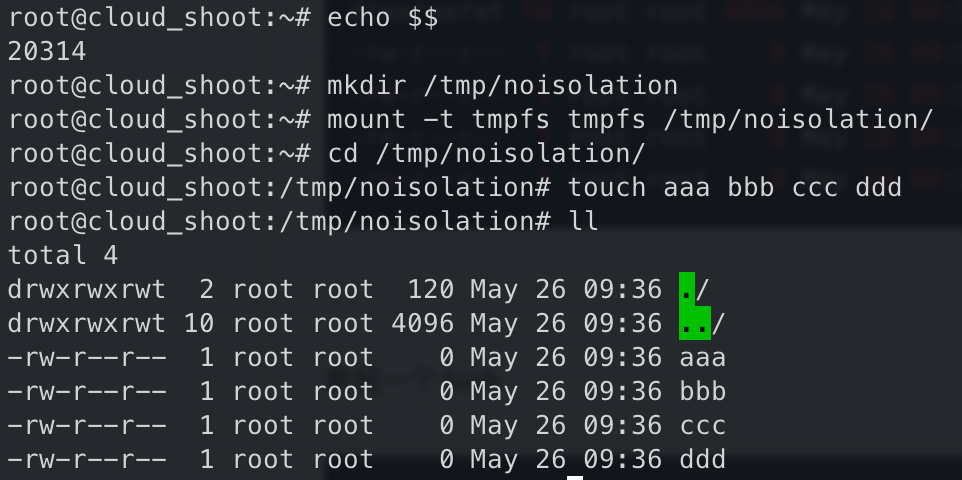
查看该 namespace 的编号,发现只有 mnt 改变了
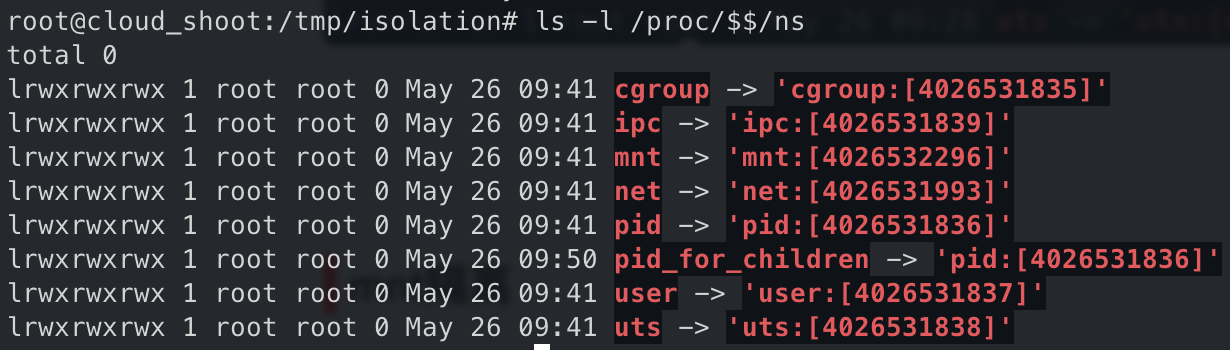
在新起的终端确认
/tmp/isolation 文件内容,文件不存在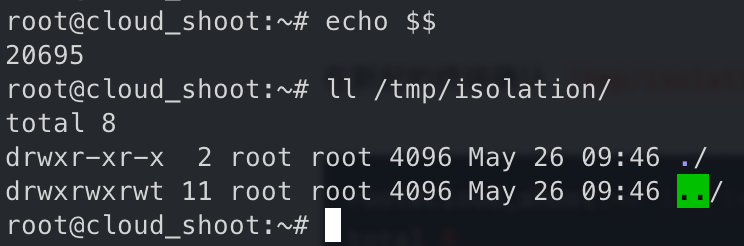
那其他命名空间呢?
C实现命名空间隔离实验[13] [14]
clone()系统调用
clone.c
直接启用通过execv启用一个子进程,到新的 /bin/bash 环境,这里没做任何隔离,父进程能做的子进程基本都可以做
UTS Namespace
可通过 clone() 函数设置
CLONE_NEWUTS 标志位实现,需要 root 权限 uts_ns.c子进程运行
hostname 查看主机名变成 container, 宿主机不变,这里注意如果是用 hostnamectl sethostname <xxx> 命令会改变宿主机的 hostname,因为这个命令是通过写文件实现的,这里并未做文件隔离IPC Namespace
可通过 clone() 函数设置
CLONE_NEWIPC 标志位实现,需要 root 权限ipc.c
ipcmk -Q 创建一个进程通信消息队列,通过 ipcs -q 查看新建的队列。 运行进程间通信隔离程序,子进程内运行 ipcs -q 看不到新建的队列PID Namespace
可通过 clone() 函数设置
CLONE_NEWPID 标志位实现,需要 root 权限pid_ns.c
运行进程隔离程序会发现我们程序的pid为1,pid为1是特殊的进程,在表1介绍中有列举一些特殊性 这里直接 ps 会发现只有当前子进程的进程号,但通过
ps -ef 或者 top 命令会查看到所有进程号,这里是因为 ps -ef 会读取 /proc 文件系统,这里还未对此文件系统进行隔离MNT Namespace
可通过 clone() 函数设置
CLONE_NEWNS 标志位实现,需要 root 权限mnt_ns.c
这里对
/proc 文件系统进行了隔离,此时在 ps -ef 或者 top 看到的也只有当前进程的进程号了,注意此程序会覆盖父进程的 /proc 系统,子进程退出后要通过 umount 或者 mount -t proc proc /proc 当然除了 /proc 还有 /dev、/sys、/tmp、/run 等一个玩具容器
先创建一个 rootfs
其中
lib/x86_64-linux-gnu 根据 ldd /bin 目录下各个命令结果的动态链接库来,我这里分别是chroot rootfs 改变根目录, 进入至新的文件系统里了,但是现在一些命名空间还没做隔离,加上上面的clone函数标志位container.c
做了主机、进程、进程间通信、文件系统(包含 /dev /proc/sys /run /tmp 目录)隔离的代码
运行后悔挂在设备文件至 rootfs/dev 等目录,想要删除 rootfs 需要
umount -R rootfs/dev rootfs/proc rootfs/sys rootfs/run rootfs/tmp rootfs/etc/* 一下User Namespace
可通过 clone() 函数设置
CLONE_NEWUSER 标志位实现,但不需要 root 权限,通过普通用户运行,安全系数更高,就算被逃逸了也是一个普通用户权限sys/capability.h头文件需要安装依赖写入/proc//uid_map(gid_map)文件的进程需要这个namespace中的CAP_SETUID (CAP_SETGID)权限,写入的进程必须是此user namespace的父或子的user namespace进程 我这编译了 gid 映射文件没成功写入,原因可参考 https://man7.org/linux/man-pages/man7/user_namespaces.7.html
/* Linux 3.19 made a change in the handling of setgroups(2) and the ‘gid_map’ file to address a security issue. The issue allowed unprivileged users to employ user namespaces in order to drop The upshot of the 3.19 changes is that in order to update the ‘gid_maps’ file, use of the setgroups() system call in this user namespace must first be disabled by writing “deny” to one of the /proc/PID/setgroups files for this namespace. That is the purpose of the following function. */
其实上述代码还涉及进程间同步问题,即有管道代码位置有点问题,有时会出现还未修改 /proc//uid_map(gid_map) 就已经获取了容器内的 uid 和 gid ,这里通过另外一种方式实现,解决进程同步问题,顺便设置了 setgroups
看了下这部分代码,发现和 Docker 的 nsexec.c 有几分相像
或者还有些疑问,因为这个是非 root 权限就可以设置的标志位,对于需要 root 权限的标志位,一般用户先创建User Namespace,然后把这个用户映射成root,在容器内用root来创建其它的Namesapce
Network Namespace
与上面几种Namespace一样,通过设置标志位
CLONE_NEWNET 即可实现网络隔离,比如 nc 监听 80 端口,并不会占用宿主机的端口到这里,需要隔离的已经隔离的差不多了,为了更加直观的演示,下面通过命令模仿Docker中的网络命名空间
Docker 在宿主机上的网络示意图
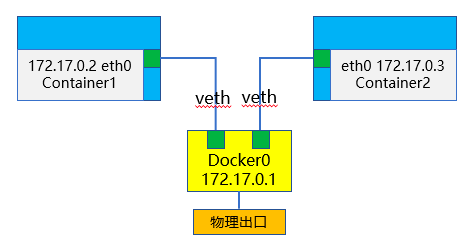
在虚拟机上查看网络情况
ip linkip命令自带网络空间隔离功能,我们可以通过如下命令来做一个Docker桥接网络
可以通过
brctl show 命令查看网桥接入的网卡情况,并且可以通过执行 ip netns exec ns1 ping 192.168.10.1 测试命名空间内的网络是否与lxcbr0网桥正常通信要想容器内访问外部网络,需要添加路由,需要域名解析需要添加dns解析
如果在虚拟机内还需要设置网卡为混杂模式
CGroups Namespace[15]
推荐阅读 Cgroup概述[16]
cgroup是Linux下的一种将进程按组进行管理的机制,在用户层看来,cgroup技术就是把系统中的所有进程组织成一颗一颗独立的树,每棵树都包含系统的所有进程,树的每个节点是一个进程组,而每颗树又和一个或者多个subsystem关联,树的作用是将进程分组,而subsystem的作用就是对这些组进行操作
cgroups (control groups) 主要包括 subsystem 和 hierarchy 两部分
1个subsystem就是一个内核模块,目前Linux支持下面12种subsystem
- cpu (since Linux 2.6.24; CONFIG_CGROUP_SCHED) 用来限制cgroup的CPU使用率。
- cpuacct (since Linux 2.6.24; CONFIG_CGROUP_CPUACCT) 统计cgroup的CPU的使用率。
- cpuset (since Linux 2.6.24; CONFIG_CPUSETS) 绑定cgroup到指定CPUs和NUMA节点。
- memory (since Linux 2.6.25; CONFIG_MEMCG) 统计和限制cgroup的内存的使用率,包括process memory, kernel memory, 和swap。
- devices (since Linux 2.6.26; CONFIG_CGROUP_DEVICE) 限制cgroup创建(mknod)和访问设备的权限。
- freezer (since Linux 2.6.28; CONFIG_CGROUP_FREEZER) suspend和restore一个cgroup中的所有进程。
- net_cls (since Linux 2.6.29; CONFIG_CGROUP_NET_CLASSID) 将一个cgroup中进程创建的所有网络包加上一个classid标记,用于tc和iptables。 只对发出去的网络包生效,对收到的网络包不起作用。
- blkio (since Linux 2.6.33; CONFIG_BLK_CGROUP) 限制cgroup访问块设备的IO速度。
- perf_event (since Linux 2.6.39; CONFIG_CGROUP_PERF) 对cgroup进行性能监控
- net_prio (since Linux 3.3; CONFIG_CGROUP_NET_PRIO) 针对每个网络接口设置cgroup的访问优先级。
- hugetlb (since Linux 3.5; CONFIG_CGROUP_HUGETLB) 限制cgroup的huge pages的使用量。
- pids (since Linux 4.3; CONFIG_CGROUP_PIDS) 限制一个cgroup及其子孙cgroup中的总进程数。
1个hierarchy可以理解为1颗cgroup树
查看当前系统支持的subsystem和当前系统已经挂载的subsystem
这里先关注 cpu 的,进入 cpu subsystem目录,创建一个组名为 tari 的cgroup,并查看当前目录
发现在subsystem创建目录会生成一些默认文件,通过控制文件里的数值,从而对资源进行限制。
如果往
cpu.cfs_quota_us文件写入100000(十万),就限制 tari 的cgroup最多能够使用1核的CPU(因为cpu.cfs_period_us配置文件默认把1核cpu分成了10万份)。写入20000,证明最多使用使用1/5核的CPU。首先,新起一个进程,运行
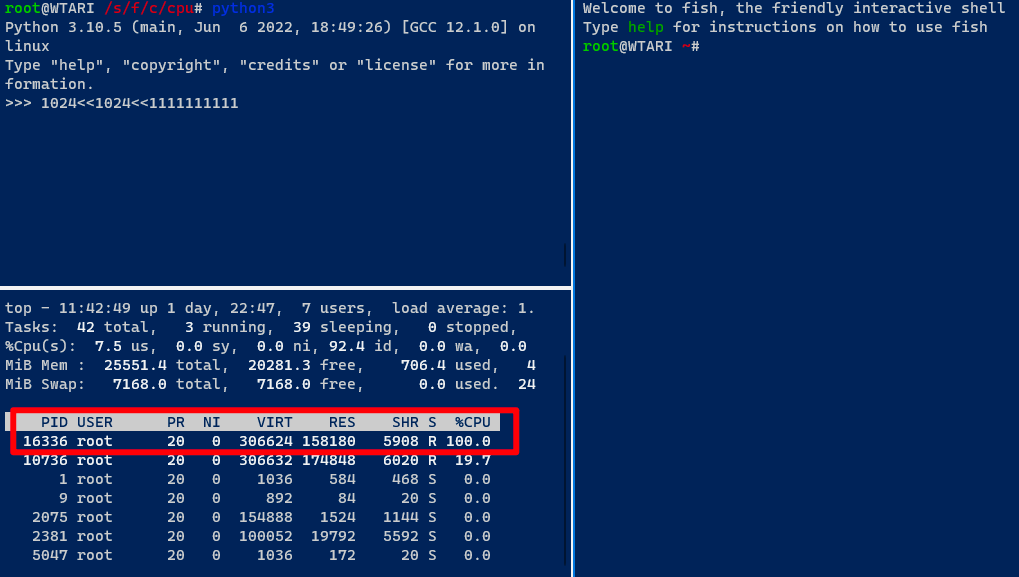
CPU 占用率为 100%,这时把 PID 16336 加入 tari cgroup
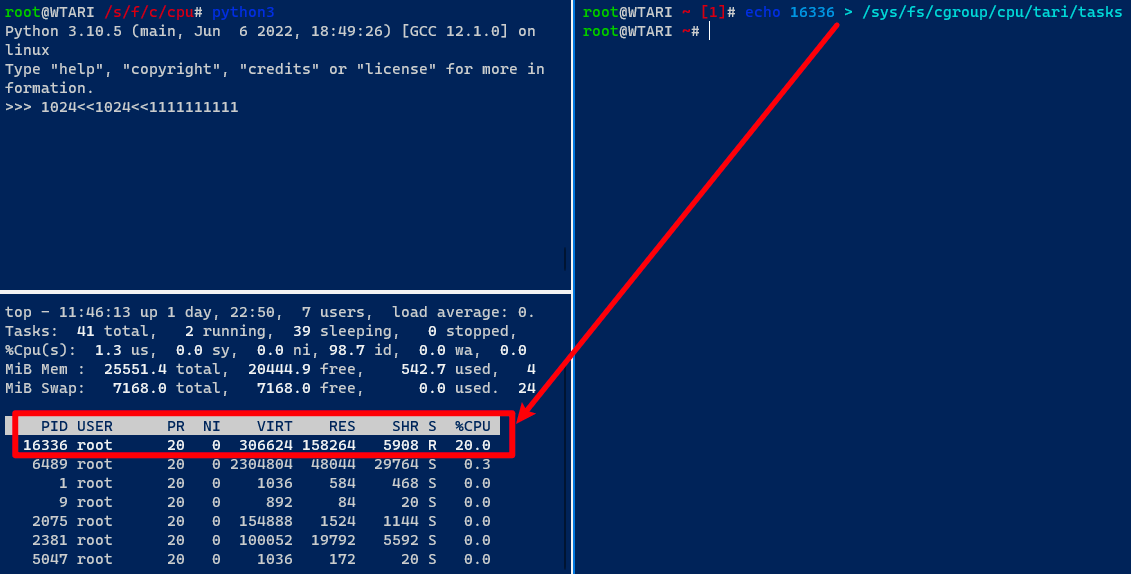
可以看到CPU占用率为20%左右,其实从写入的配置文件名 cpu.cfs_quota_us 也易知是 CPU 配额,容器里的配额其实也是这么一回事,对于其他资源的限制,也是类似的思路
Docker 也是通过这种方式实现对容器进行资源隔离[17]
默认Docker启动一个容器后会在
/sys/fs/cgroup 目录下的各个subsystem目录生成以容器ID为名字的目录,如Docker中命名空间隔离的实现
Docker 底层即 runc:

src/github.com/opencontainers/runc/init.go
import ("... _ "github.com/opencontainers/runc/libcontainer/nsenter" ...")—>
src/github.com/opencontainers/runc/libcontainer/nsenter/nsenter.go
__attribute__((constructor)) init(void) 的 nsexec(); 这段 cgo 利用 gcc constructor 特性让这段C代码先于Go的runtime启动之前执行nsenter_gccgo.go 中的 if AlwaysFalse 条件一开始我以为是会某种条件满足,实际并不用管,这只是如注释所说为了编译器可以成功编译它,正在是通过
__attribute__ 特殊构造函数调的—>
nsexec.c
nsexec(); 实现命名空间和资源隔离的核心代码,与我们在 User Namespace 改进后的代码有几分相似因为Docker需要支持rootless等场景下的命名空间隔离,此外由表1知一些老的内核版本不一定支持或实现了较新的(如 USER)命名空间。Docker为了更高的可拓展性,不能直接像在 【C实现命名空间隔离实验】 小节一样把相应的标志位置于
clone 函数内,所以 Docker 结合 clone、unshare和setns实现。因个人对 runc 和 docker 之间的交互逻辑目前处于一种看懂状态,感觉别人讲的更好,推荐阅读 runc源码分析 [18]
想进一步了解Docker,推荐阅读 理解Docker系列文章[19]
命名空间隔离不当漏洞 CVE-2020-15257
该漏洞是 containerd 层导致的,可参照 Docker (远程) Debug 调试环境搭建 - TARI TARI - 0x02 Docker架构组成 部分
漏洞环境
环境部署
漏洞影响版本
- containerd 1.3.x, 1.2.x, 1.4.x版本
复现组件版本
利用条件
网络模式为host的情况下,即容器启动时指定
--net=host 参数漏洞描述
Access controls for the shim’s API socket verified that the connecting process had an effective UID of 0, but did not otherwise restrict access to the abstract Unix domain socket. This would allow malicious containers running in the same network namespace as the shim, with an effective UID of 0 but otherwise reduced privileges, to cause new processes to be run with elevated privileges.
前置知识
Unix套接字
在Linux系统中,可通过Unix域套接字在同一个主机上的进程之间进行通信,它的API调用方法和普通的TCP/IP的套接字一样,也是调用socket函数创建一个套接字,域设置成AF_UNIX
在调用socket()函数获得新创建的Unix域套接字的文件描述符之后,再调用bind()函数将它绑定到一个本地地址上,此时需要创建并初始化一个sockaddr_un结构体,如下所示:
第一个字段
sa_family_t 需要设置成 AF_UNIX,第二个字段 sun_path 表示的是一个路径名,它分为两种:- 普通的文件路径:
它是一个合法的Linux文件路径,以
NULL结尾。在绑定一个Unix域套接字时,会在文件系统中的相应位置上创建一个文件,当不再需要这个Unix域套接字时,可以使用remove()函数或者unlink()函数将这个对应的文件删除。如果在文件系统中,已经有了一个文件和指定的路径名相同,则绑定会失败。- 抽象名字空间路径:
抽象名字空间路径以
NULL开始,后面可以跟任何数据,甚至可以是NULL,可以不以NULL结尾。相对于普通的文件路径,这种地址在文件系统上并没有实际的文件与它相对应。也就是说,它不会在文件系统中创建出一个新的文件。在Unix域套接字的文件描述符关闭的时候就会自动消失,所以无需担心与文件系统中已存在的文件产生命名冲突,也不需要在使用完套接字之后删除附带产生的这个文件。
docker网络模式
在使用docker run命令创建并运行容器时,可以使用–network选项指定容器的网络模式。
Docker有以下4种网络模式:
- none:这种模式下容器内部只有loopback回环网络,没有其他网卡,不能访问外网,完全封闭的网络;
- container:指定一个已经存在的容器名字,新的容器会和这个已经存在的容器共享一个网络命名空间,IP、端口范围也一起在这两个容器中共享;
- bridge:这是docker默认的网络模式,会为每一个容器分配网络命名空间,设置IP,保证容器内的进程使用独立的网络环境,使得容器和容器之间、容器和主机之间实现网络隔离;
- host:这种模式下,容器和主机已经没有网络隔离了,它们共享同一个网络命名空间,容器的网络配置和主机完全一样,使用主机的IP地址和端口,可以查看到主机所有网卡信息、网络资源,在网络性能上没有损耗。
但也正是因为没有网络隔离,容器和主机容易产生网络资源冲突、争抢,以及其他的一些问题。本文所述漏洞也是在这种模式下产生的。
漏洞原因
每次启动一个容器时,containerd会创建一个新的containerd-shim进程,由containerd-shim进程(而不是containerd)来直接控制容器的整个生命周期。
containerd在创建containerd-shim之前,会创建一个Unix域套接字,设置的是抽象名字空间路径:
注意最后一行中,address前面加上了一个
\x00,这个就表示抽象名字空间路径的Unix域套接字。containerd传递Unix域套接字文件描述符给containerd-shim。containerd-shim在正式启动之后,会基于父进程(也就是containerd)传递的Unix域套接字文件描述符,建立gRPC服务,对外暴露一些API用于container、task的控制: containerd/shim.proto at v1.4.2 · containerd/containerd · GitHub
此时,containerd-shim做为server向外提供服务,containerd做为client,调用containerd-shim提供的API实现对容器的间接管理。
抽象Unix域套接字没有权限限制,所以只能靠连接进程的UID、GID做访问控制,限定了只能是root(UID=0,GID=0)用户才能连接成功。
通过访问/proc/net/unix文件,可以获取到当前网络命名空间下所有的Unix域套接字信息。
在默认情况下,docker run启动的容器的网络模式是bridge,容器和主机之间实现了网络隔离,所以在容器内部读取/proc/net/unix文件,看不到任何信息,如下所示:
但是在host模式下,由于容器和主机共享同一个网络命名空间,容器能访问到主机中的所有网络资源,所以在容器内部读取/proc/net/unix文件,显示的就是真实主机中的信息,如下所示:
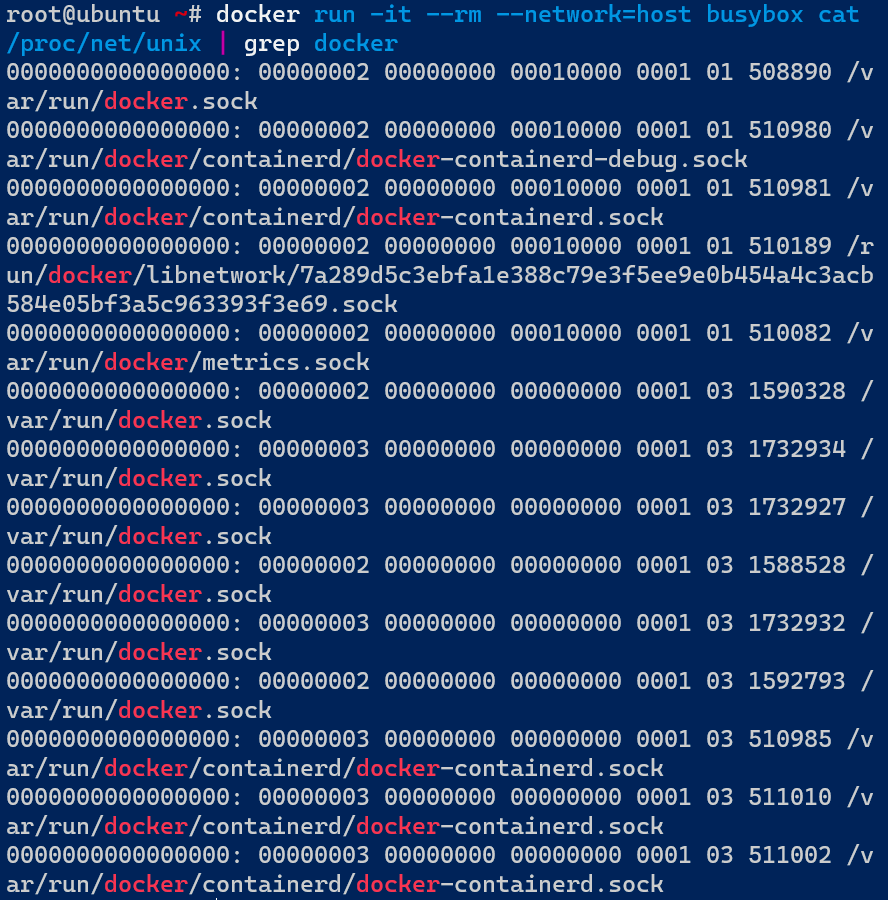
- /var/run/docker.sock:Docker Daemon监听的Unix域套接字,用于Docker client之间通信;
- /run/containerd/containerd.sock:containerd监听的Unix域套接字,Docker Daemon、ctr可以通过它和containerd通信;
- @/containerd-shim/3d6a9ed878c586fd715d9b83158ce32b6109af11991bfad4cf55fcbdaf6fee76.sock:
这个就是上文所述的,containerd-shim监听的Unix域套接字,containerd通过它和containerd-shim通信,控制管理容器。
/var/run/docker.sock、/run/containerd/containerd.sock这两者是普通的文件路径,虽然容器共享了主机的网络命名空间,但没有共享mnt命名空间,容器和主机之间的磁盘挂载点和文件系统仍然存在隔离,所以在容器内部仍然不能通过/var/run/docker.sock、/run/containerd/containerd.sock这样的路径连接对应的Unix域套接字。
也就是说:
- host模式下,容器共享了主机的网络命名空间,也就能够去连接
@/containerd-shim/3d6a9ed878c586fd715d9b83158ce32b6109af11991bfad4cf55fcbdaf6fee76.sock
这一类的抽象Unix域套接字。
- 而且在默认情况下,容器内部的进程都是以root用户启动的,所以也能通过UnixSocketRequireSameUser的校验。
在这两者的共同作用下,容器内部的进程就可以像主机中的containerd一样,连接containerd-shim监听的抽象Unix域套接字,调用containerd-shim提供的各种API,从而实现容器逃逸。
漏洞利用
推荐阅读:CVE-2020-15257 EXP 开发 ,因为与 containerd-shim 通信与dockerd通信有点不一样,构造传参麻烦些,需要知道containerd-shim的入参
下面直接用集成至 cdk 的 exp 演示
在容器内执行命令cat /proc/net/unix|grep -a “containerd-shim”,查看结果确认是否可看到抽象命名空间Unix域套接字
在攻击端监听1234端口,然后下载漏洞利用工具CDK,并将其传入容器/tmp目录下:
运行工具,执行反弹shell命令,验证得到一个宿主机的shell:
注:关于该漏洞在利用时出现类似以下内容的问题,可以暂时参考issue #74。
漏洞修复
在最新发布的1.3.9和1.4.3版本中,抽象Unix域套接字已经改成了普通文件路径的Unix域套接字
因为containerd和containerd-shim都在容器外部,所以它们之间的连接、通信不受影响;因为有mnt命名空间的隔离,所以在host模式下,容器内部也无法访问普通文件路径的Unix域套接字。也就修复了上述漏洞。