 K8S 网络之 Cilium 源码分析
K8S 网络之 Cilium 源码分析type
status
date
slug
summary
tags
category
icon
password
0x01 一些官方介绍
都是一些概念,浏览一遍即可,没说很具体
Kubernetes 网络模型


Kubernetes 网络解决四方面的问题:
- 一个 Pod 中的容器之间通过本地回路(loopback)通信。
- 集群网络在不同 Pod 之间提供通信。
- Service API 允许你向外暴露 Pod 中运行的应用, 以支持来自于集群外部的访问。
- Ingress 提供专门用于暴露 HTTP 应用程序、网站和 API 的额外功能。
- 你也可以使用 Service 来发布仅供集群内部使用的服务。


集群网络系统


- 高度耦合的容器间通信:这个已经被 Pod 和
localhost通信解决了。
- Pod 间通信:这是本文档讲述的重点。
- Pod 与 Service 间通信:涵盖在 Service 中。
- 外部与 Service 间通信:也涵盖在 Service 中。


0x02 不安装网络插件Pod本地通信
containerd 通过 runC 创建的容器,需要直接通过宿主机网络通信
在master节点创建记得先把污点去掉~ kubectl describe node 把 taint 里面的都 kubectl taint nodes archlinux node-role.kubernetes.io/control-plane- 或 kubectl taint nodes --all node-role.kubernetes.io/control-plane-

使用主机网络
正常创建
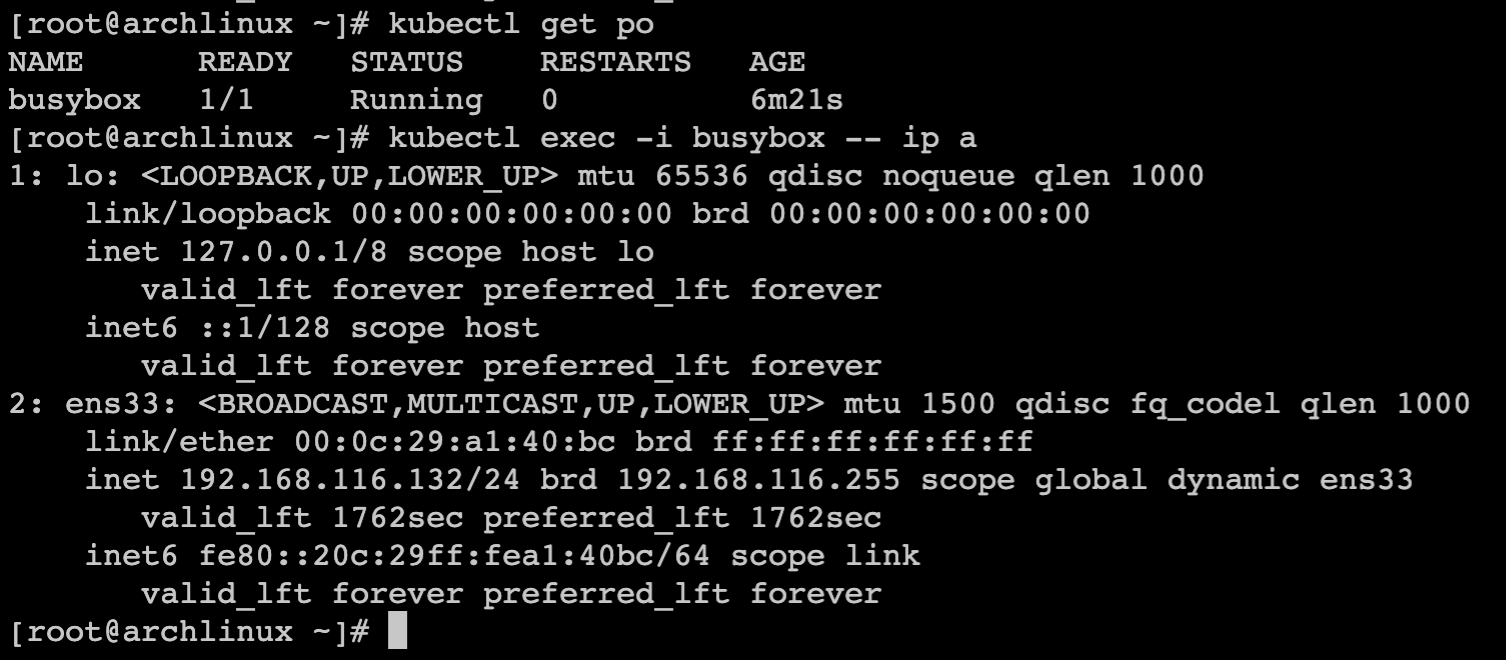
此时Pod使用的网卡为宿主机网络
0x03 安装插件Pod通信 - cilium
对于不同的网络插件,下面可能会有较大的差异
安装 cilium 的操作系统要求(新版 archlinux 默认满足)
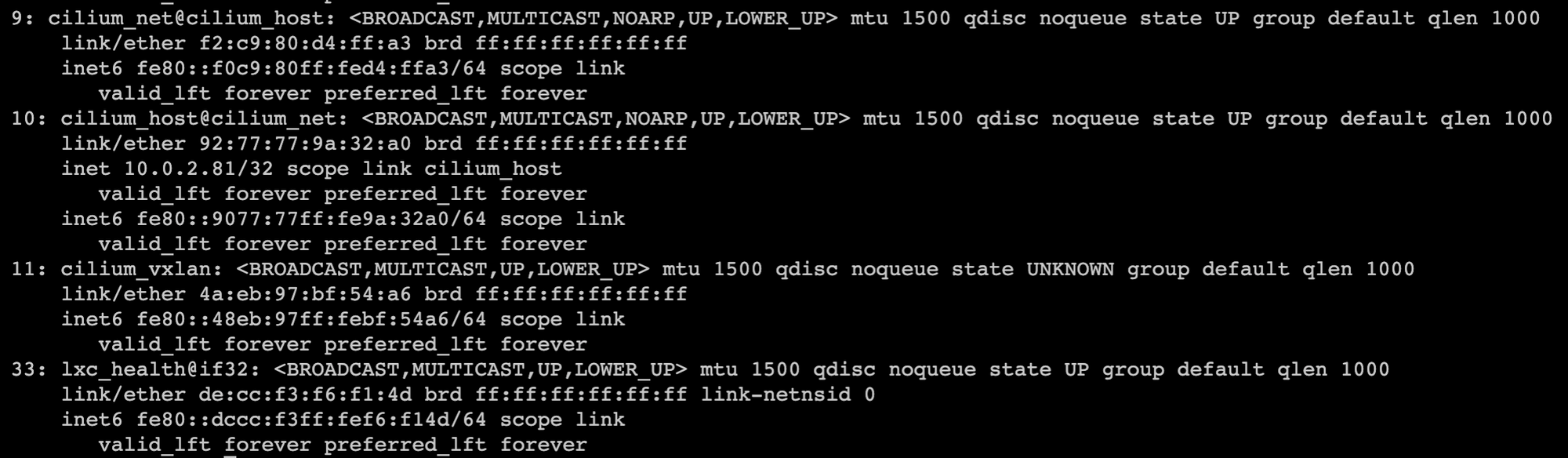
安装完插cilium件后,master节点宿主机会多出几个网卡
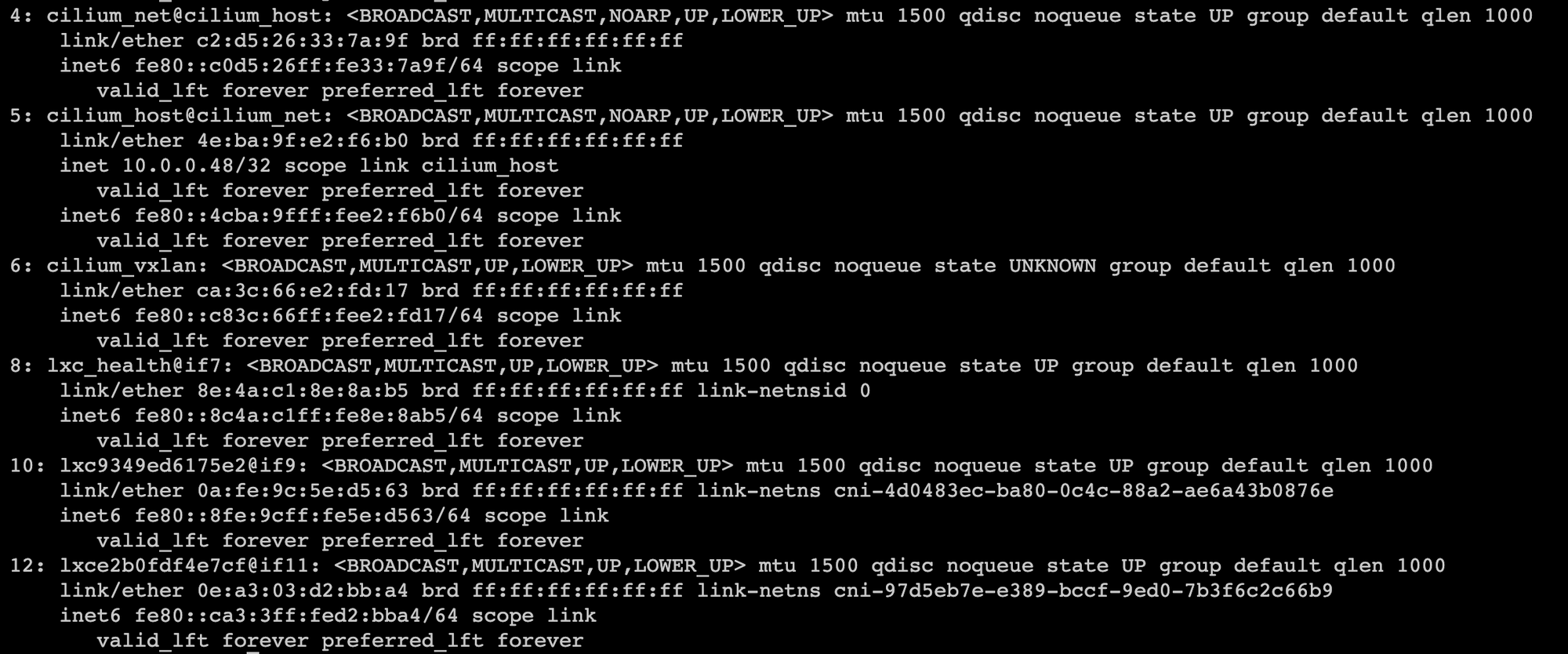
节点也会多出张网卡,不过和master节点有点不同
接下来分析一下 cilium 官方的安装 yaml 文件,这个很长的安装文件由几部分组成
- # Source: cilium/templates/cilium-agent-serviceaccount.yaml
- # Source: cilium/templates/cilium-operator-serviceaccount.yaml
- # Source: cilium/templates/cilium-configmap.yaml
- # Source: cilium/templates/cilium-agent-clusterrole.yaml
- # Source: cilium/templates/cilium-operator-clusterrole.yaml
- # Source: cilium/templates/cilium-agent-clusterrolebinding.yaml
- # Source: cilium/templates/cilium-operator-clusterrolebinding.yaml
- # Source: cilium/templates/cilium-agent-daemonset.yaml
- # Source: cilium/templates/cilium-operator-deployment.yaml
1-2 4-7 是定义了Pod的sa用户以及相应的集群角色和集群角色绑定
3 通过 configmap 定义了一些配置项
8 为 cilium agent 端部署文件
9 为 cilium operator 端部署文件
关于 Agent 和 Operator 的描述


- Agent 运行于集群中的每个节点上,通过Kubernetes或API接收描述网络、服务负载均衡、网络策略以及可视化和监控需求的配置。它监听来自编排系统(如Kubernetes)的事件,以了解容器或工作负载何时启动和停止。Agent 也管理Linux内核使用的eBPF程序,用于控制这些容器内/外的所有网络访问
- Operator 一般位于master节点上,负责用于IP地址管理(IPAM),给Pod分配新的IP CIDR地址和更新kvstore心跳
0x01 路由


默认情况下,Cilium 使用 VXLAN 封包协议,当然可以在 https://github.com/cilium/cilium/blob/v1.9/install/kubernetes/quick-install.yaml#L107-L112 tunnel 中设置
- vxlan
- geneve
- disabled
Encapsulation Mode | Port Range / Protocol |
VXLAN (Default) | 8472/UDP |
Geneve | 6081/UDP |
vxlan 和 geneve 的区别可见 VXLAN vs. GENEVE:隧道协议之争 (sdnlab.com)

查看监听端口即可知道使用的是哪种,Geneve 比 VXLAN 新,为 VXLAN 的拓展协议,考虑兼容性一般用 VXLAN 多些
当选项为 disabled 时,启用原生包转发,本机数据包转发模式利用Cilium运行网络的路由功能,而不是执行VXLAN等封包。
使用原生转发需要连接集群节点的网络必须能够路由PodCIDR,即在 cilium-configmap 中配置
ipv4-native-routing-cidr: x.x.x.x/y。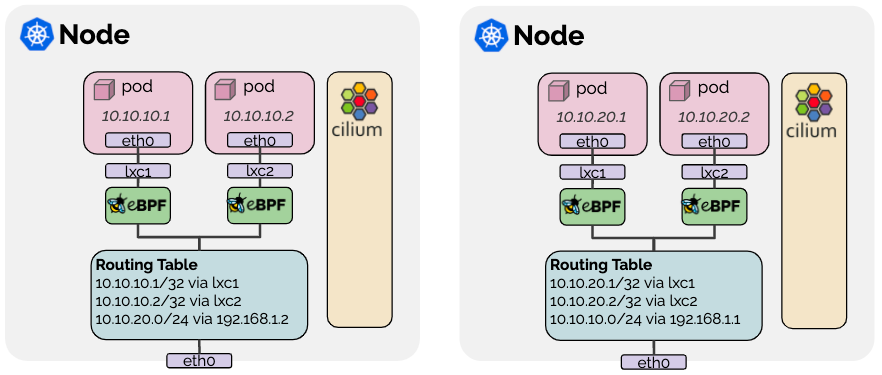
这里的 Pod 内的 eth0 和 lxc1 网桥连接和之前我在 Linux命名空间机制及其隔离不当导致的漏洞 | tari’s Blog 文章处的实验是类似的,不过路由不走 Linux 内核,直接通过 eBPF转发数据包
0x02 IP管理(IPAM)
0x01 Cilium 集群作用域(默认)
configmap 配置:https://github.com/cilium/cilium/blob/v1.9/install/kubernetes/quick-install.yaml#L149C19-L151
Cilium Opertor 通过
v2.CiliumNode资源来管理每个节点的PodCIDR。这种模式的优点是,它不依赖于 K8S 为每个节点分发的PodCIDR。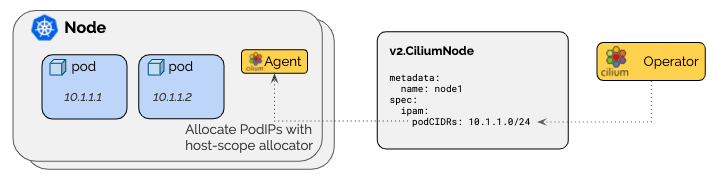
在此模式下,Cilium Agent 将在启动时等待,直到通过Cilium Node
v2.CiliumNode对象通过v2.Cilium节点中设置的资源字段为所有启用的地址族提供podCIDRs范围:输出
spec.ipam.podCIDRs 字段正常,可以看到和集群初始化的 CIDR 是不一样的0x02 K8S主机作用域
configmap 配置为
ipam: kubernetes 启用 K8S IPAM模式,并将地址分配委托给集群中的节点。IP由K8S在与每个节点关联的PodCIDR范围之外分配的。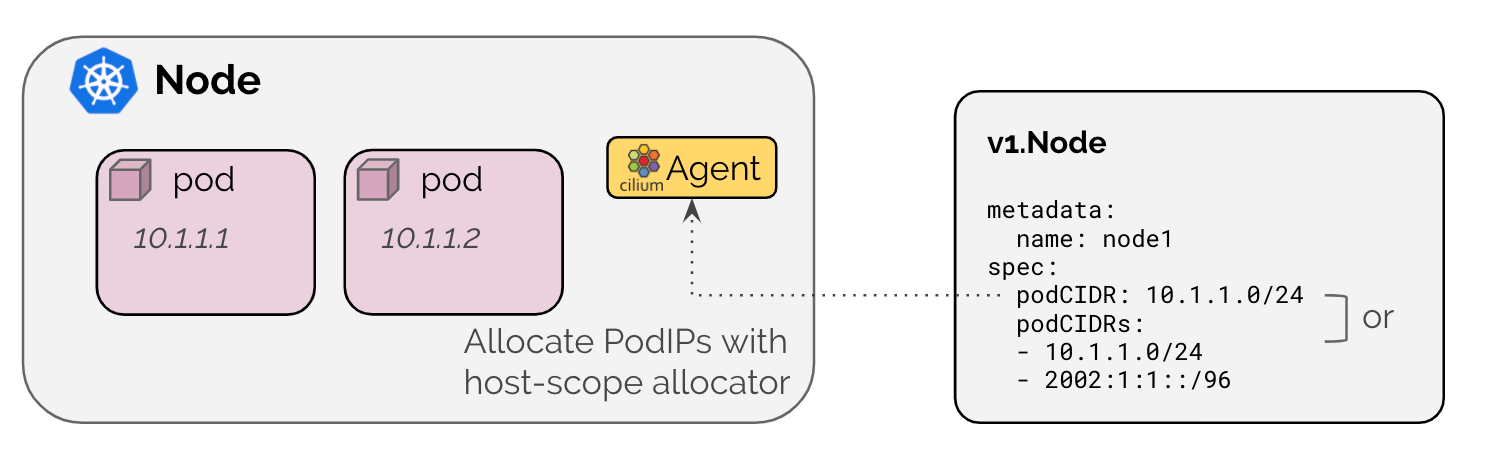
在此模式下,Cilium Agent将在启动时等待,直到通过Kubernetes
v1.Node对象通过以下方法启用地址族提供PodCIDR范围- 通过
v1.Node resource字段
Field | Description |
spec.podCIDRs | IPv4 and/or IPv6 PodCIDR range |
spec.podCIDR | IPv4 or IPv6 PodCIDR range |
需要kube-controller-manager通过--allocate-node cidrs启动指定应分配PodCIDR范围
- 通过
v1.Node annotation字段
Annotation | Description |
network.cilium.io/ipv4-pod-cidr | IPv4 PodCIDR range |
network.cilium.io/ipv6-pod-cidr | IPv6 PodCIDR range |
network.cilium.io/ipv4-cilium-host | IPv4 address of the cilium host interface |
network.cilium.io/ipv6-cilium-host | IPv6 address of the cilium host interface |
network.cilium.io/ipv4-health-ip | IPv4 address of the cilium-health endpoint |
network.cilium.io/ipv6-health-ip | IPv6 address of the cilium-health endpoint |
基于annotation的机制主要与旧的Kubernetes版本结合使用,这些版本还不支持spec.podCIDR,但支持IPv4和IPv6。
0x03 Masquerading
configmap设置字段:https://github.com/cilium/cilium/blob/v1.9/install/kubernetes/quick-install.yaml#L119-L120
用于pod的IPv4地址是从RFC1918私有地址块分配的,不可公开路由。Cilium将自动将离开集群的所有流量的源IP地址masquerade(伪装)为K8S节点的IPv4地址,因为节点的IP地址已经可以在网络上路由。
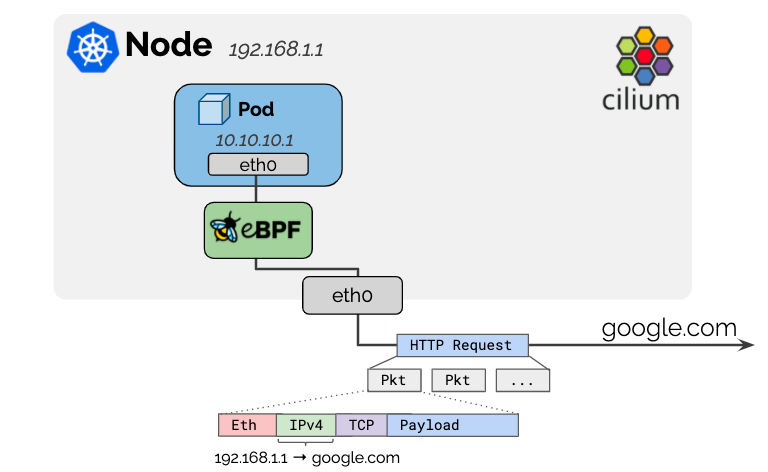
对于IPv6地址,只有在使用iptables实现模式时才执行masquerading,可以通过选项
enable-ipv4-masquerade:false和 enable-ipv6-masquerady:false 禁用。当然,也可以通过
ipv4-native-routing-cidr: 10.0.0.0/8 或 ipv6-native-routing-cidr: fd00::/100 来取消masquerading在 cilium masquerading 实现有两种
- 基于 eBPF(默认)
需要Linux内核大于等于4.19,并且 configmap 配置为
bpf.masquerade=trueeBPF虽高效,但目前存在一些问题
- 当用 cilium 完全代替 kube-proxy时不支持
--nodeport-addresses- 官方说后面会解决
- Pod → 外部K8S节点 IP 通信无法 masquerading
- 目前不支持 IPv6流量masquerading
- 基于 iptables
默认 masquerade 所有从非 Cilium 网口经过的流量
当然可以通过
egress-masquerade-interfaces: eth0 参数指定 masquerade 特定网口的流量0x04 IPv4 分段
IPv4 分片处理是指当 IP 数据包太大而无法在网络上传输时,路由器将其分成更小的数据包进行传输。在这个过程中,每个数据包包含有关原始数据包位置和大小的信息。
Cilium 使用 IPv4 分片来帮助处理大型数据流,并降低网络延迟。此外,它还可以通过缓存和重组分片数据包来提高网络吞吐量和性能。
0x05 网络策略(安全)
Cilium 支持
- K8S原生L3-L4的POD入站和出站网络策略
- 通过CRD(CustomResourceDefinition) 定义 CiliumNetworkPolicy 拓展策略以在L3-L7层支持入站和出站网络策略
- CiliumClusterwideNetworkPolicy 集群范围 CRD,由Cilium强制执行的集群范围的策略
目前存在疑问🤔️
- kubelet 和 cilium 是如何协调,在容器中创建出网卡的,可以看看 [1] 这篇文章,好像是 调用 cni 二进制程序做到的,难道这部分是写在 cni 里的?https://github.com/containernetworking/cni/blob/main/SPEC.md
- 容器内的 vxlan 是如何跨容器进行通信,以及这个 vxlan 是如何被维护的
0x04 Cilium 和 kubelet源码阅读
- kubelet 版本: v1.26.3 commit: 9e644106593f3f4aa98f8a84b23db5fa378900bd
- Cilium 版本: v1.9 commit: 638f8ddac2ffc05a036df66ccf9c5a920c9e5323
由上可知, Cilium 部署时主要部署2个组件
- cilium-operator deployment
- cilium-agent daemonset
0x01 Cilium operator
operator 默认为 cluster-pool 模式作为 ipam mode,主要负责网段划分
该模式通过
v2.CiliumNode资源来管理每个节点的PodCIDR[github.com/cilium/cilium/operator]
• main.go:314 -
alloc.Init()[src/github.com/cilium/cilium/pkg/ipam/allocator/clusterpool]
• clusterpool.go:69 -
newCIDRSets(false, operatorOption.Config.ClusterPoolIPv4CIDR, operatorOption.Config.NodeCIDRMaskSizeIPv4)• clusterpool.go:133 -
newCIDRSet(isV6, addr, cidr, maskSize)由上调用栈知 ipam 会依次遍历多个 cidr,一个网段消耗完了继续使用下一个网段,和 K8S 本身的 PodCIDR 就没有很大关系了
0x02 Cilium Agent
Agent 组件会从其对应的子网段出再去划分出每一个 pod ip
containerd启动流程调用栈
众所周知,程序执行时,golang的包被 import 引入时,就会查看包内是否存在
init() 函数,有则掉用,比 main() 函数更先调用[github.com/containerd/containerd/cmd/containerd]
• main.go:28 -
[github.com/containerd/containerd/cmd/containerd/builtins]
• cri.go:22
[github.com/containerd/containerd/pkg/cri]
• cri.go:43 -
config := criconfig.DefaultConfig()[github.com/containerd/containerd/pkg/cri/config]
这里初始化了默认的 cni 路径
NetworkPluginBinDir: "/opt/cni/bin"、NetworkPluginConfDir: "/etc/cni/net.d", 、默认运行时runc、监听地址等• config_unix.go:30 - func DefaultConfig() PluginConfig
[github.com/containerd/containerd/pkg/cri]
• cri.go:61 -
pluginConfig := ic.Config.(*criconfig.PluginConfig)• cri.go:66 -
到这里网络插件相关路径就初始化的差不多啦
接下来就是正常的 main 函数流程,查看有没有设置 config 参数,从而去覆盖默认的参数
• main.go:115 -
config = defaultConfig()• main.go:122 -
configPath := context.GlobalString("config")• main.go:125 -
srvconfig.LoadConfig(configPath, config);• main.go:195 -
server.New(ctx, config)• server.go:112 -
plugins, err := LoadPlugins(ctx, config)从 Kubelet源码分析 | tari’s Blog 知,kubelet 通过调用 containrd 创建 Pod。
Containerd 创建 Pod 网络在创建 Pod 中的调用栈
[github.com/containerd/containerd/vendor/k8s.io/cri-api/pkg/apis/runtime/v1]
• api.proto:40 -
rpc RunPodSandbox(RunPodSandboxRequest) returns (RunPodSandboxResponse) {}为啥不是 github.com/containerd/containerd/third_party/k8s.io/cri-api/pkg/apis/runtime/v1alpha2?
因为
RunPodSandbox 的方法的接收器为 criService,而 criService 实现的是 CRIService,CRIService 接口里定义了 runtime.RuntimeServiceServer,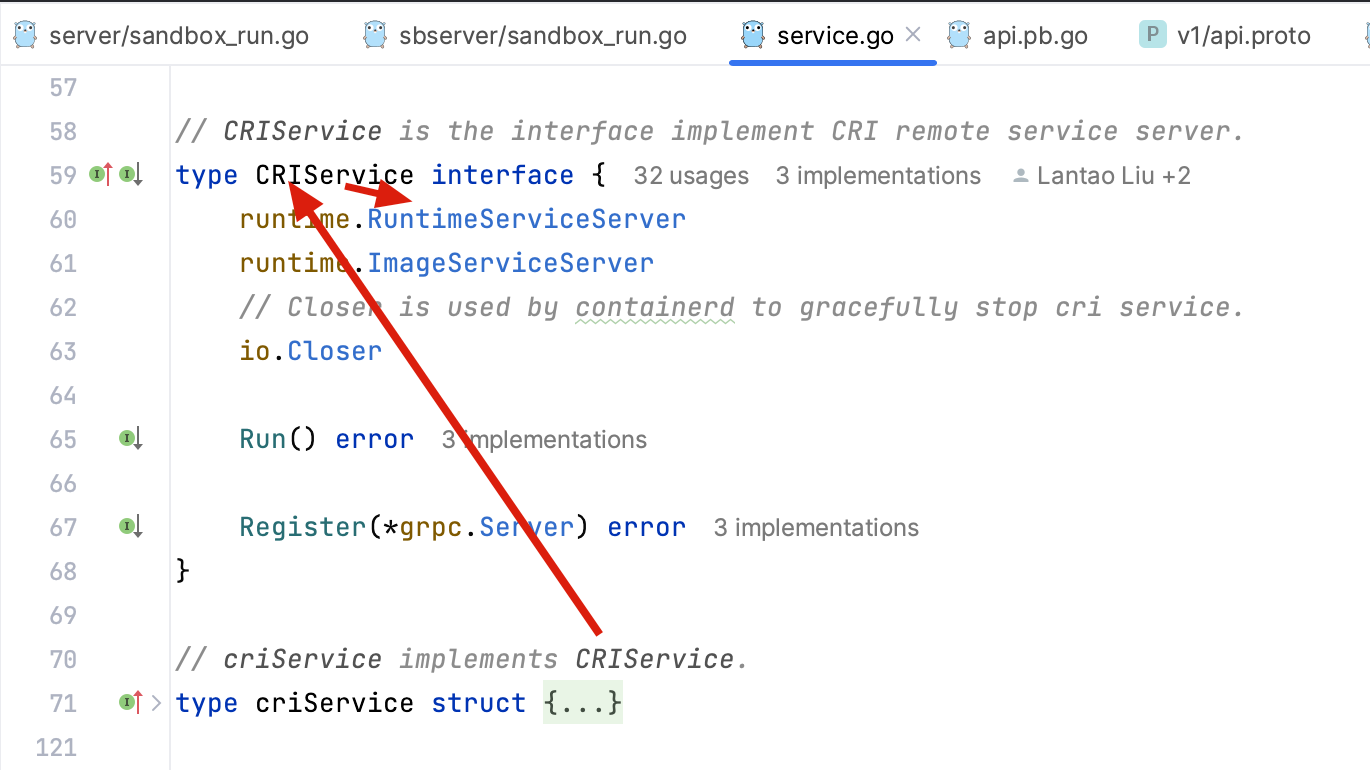
RuntimeServiceServer 接口对应 api.proto:34 service RuntimeService {[github.com/containerd/containerd/pkg/cri/server]
• sandbox_run.go:58 -
func (c *criService) RunPodSandbox(ctx context.Context, r *runtime.RunPodSandboxRequest) (_ *runtime.RunPodSandboxResponse, retErr error)• sandbox_run.go:59 -
config := r.GetConfig()• sandbox_run.go:91 - 101
--> RuntimeHandler: r.GetRuntimeHandler(),
注意这个 Goland 自动跳转是不准的,会跳到
PodSandboxStatus 里,正确的应该是跳到 RunPodSandboxRequest 里 [github.com/containerd/containerd/vendor/k8s.io/cri-api/pkg/apis/runtime/v1]
api.pb.go:1499-1504
对应
[github.com/containerd/containerd/vendor/k8s.io/cri-api/pkg/apis/runtime/v1]
api.proto:455-464
462行带有一个官方文档
即这个
RuntimeHandler 就是我们平常认识的运行时 runC、Kata、gVisor网络设置
[github.com/containerd/containerd/pkg/cri/server]
• sandbox_run.go:336 或 • sandbox_run.go:457 -
c.setupPodNetwork(ctx, &sandbox); • sandbox_run.go:531 -
func (c *criService) setupPodNetwork(ctx context.Context, sandbox *sandboxstore.Sandbox) error• sandbox_run.go:536 -
netPlugin = c.getNetworkPlugin(sandbox.RuntimeHandler)想知道这个 RuntimeHandler 是什么
sandbox.RuntimeHandler 在 sandbox_run.go:91 - 101 中初始化,即对应上面的 RuntimeHandler: r.GetRuntimeHandler()
• sandbox_run.go:367 -
netPlugin.Setup(ctx, id, path, opts...)[github.com/containerd/containerd/vendor/github.com/containerd/go-cni]
• cni.go:163 -
c.attachNetworks(ctx, ns)• cni.go:218 -
go asynchAttach(ctx, i, network, ns, &wg, rc)• cni.go:206 -
n.Attach(ctx, ns)[github.com/containerd/containerd/vendor/github.com/containerd/go-cni]
• namespace.go:33 -
n.cni.AddNetworkList(ctx, n.config, ns.config(n.ifName))[github.com/containerd/containerd/vendor/github.com/containernetworking/cni/libcni]
• api.go:422 -
c.addNetwork(ctx, list.Name, list.CNIVersion, net, result, rt)• api.go:395 -
pluginPath, err := c.exec.FindInPath(net.Network.Type, c.Path) 这里的
c 为 CNIConfig 即上面 containerd启动流程调用栈 里分析出来的路径 /opt/cni/bin ,net.Network.Type 经分析为 /etc/cni/net.d/05-cilium.conf 里的 type 字段所以
pluginPath 为 /opt/cni/bin/cilium-cni• api.go:414 -
invoke.ExecPluginWithResult(ctx, pluginPath, newConf.Bytes, c.args("ADD", rt), c.exec)
[github.com/containerd/containerd/vendor/github.com/containernetworking/cni/pkg/invoke]• exec.go:126 -
stdoutBytes, err := exec.ExecPlugin(ctx, pluginPath, netconf, args.AsEnv())即kubelet 在创建 Pod 时会根据 cni 标准调用
/opt/cni/bin/cilium-cni 二进制文件来为当前 Pod 创建网络。cilium-cni 创建 Pod 网络调用栈
先看 main 函数
cniVersion 参数指定插件支持的 cni 版本,这里最高支持 0.3.1,这与 https://github.com/containernetworking/cni/blob/spec-v0.3.1/SPEC.md#parameters 文档描述 cni 插件 0.3.1 必须支持的一致,即容器增加网络、删除网络和直接运行 cilium-cni 时,返回支持的 cni 版本(注意与spec-v1.0版本是有不同的),可以看这个表 https://github.com/containernetworking/cni/blob/main/SPEC.md#released-versions
跟进 cmdAdd研究如何增加容器网络
[src/github.com/cilium/cilium/plugins/cilium-cni]
• cilium-cni.go:80 -
skel.PluginMain(cmdAdd,• cilium-cni.go:358 -
configResult, err := c.ConfigGet()• config.go:25 -
resp, err := c.Daemon.GetConfig(nil)[github.com/cilium/cilium/api/v1/client/daemon]
• daemon_client.go:99 -
通过调用接口获取配置向
cilium-agent (作为服务端)获取配置cilium-agent 接口定义[github.com/cilium/cilium/api/v1/server/restapi]
• cilium_api_api.go:629 -
o.handlers["GET"]["/config"] = daemon.NewGetConfig(o.context, o.DaemonGetConfigHandler)最终调用
[github.com/cilium/cilium/daemon/cmd]
• config.go:108 -
func (h *getConfig) Handle(params GetConfigParams) middleware.Responder接下来根据从服务端读到的配置,选择相应的虚拟化网卡模式
个人觉得主要区别是 veth 实现逻辑更简单,ipvlan 更复杂,但相应的 ipvlan 在使用 vepa 模式时,性能更高
[src/github.com/cilium/cilium/plugins/cilium-cni]
• cilium-cni.go:381 -
case datapathOption.DatapathModeVeth:• cilium-cni.go:410 -
case datapathOption.DatapathModeIpvlan:默认一般用 veth 模式较多
• cilium-cni.go:387 -
veth, peer, tmpIfName, err = connector.SetupVeth(ep.ContainerID, int(conf.DeviceMTU), ep)创建 veth pair,并通过 SetupVethWithNames 设置 mac mtu等信息
- host 侧网卡命名: lxc + sha256(containerID)),如 lxceb7fcc8be80b63438e0f737d76aae32e9d2aabc857c33def4ec6098e5c2c7624;
- container 侧网卡命名:tmp + maxLen(containerID, 5)

SetupVethWithNames(lxcIfName, tmpIfName, mtu, ep) 底层通过系统调用创建 AF_NETLINK 套接字使用原始套接字向Linux内核发送Netlink消息(用户态 → 内核态)创建 veth[github.com/cilium/cilium/vendor/github.com/vishvananda/netlink/nl]
• nl_linux.go:428 -
s, err = getNetlinkSocket(sockType)• nl_linux.go:516 -
fd, err := unix.Socket(unix.AF_NETLINK, unix.SOCK_RAW|unix.SOCK_CLOEXEC, protocol)• nl_linux.go:446 -
s.Send(req)[github.com/cilium/cilium/plugins/cilium-cni]
• cilium-cni.go:400 -
netlink.LinkSetNsFd(*peer, int(netNs.Fd()))• cilium-cni.go:405 -
connector.SetupVethRemoteNs(netNs, tmpIfName, args.IfName)上述两行代码实现把容器侧的网卡放入新的命名空间中,并重命名网卡名称
配置容器侧路由
• cilium-cni.go:481 -
prepareIP(ep.Addressing.IPV4, false, &state, int(conf.RouteMTU))• cilium-cni.go:238 -
state.IP4routes, err = connector.IPv4Routes(state.HostAddr, mtu);
• cilium-cni.go:506- macAddrStr, err = configureIface(ipam, args.IfName, &state)代码执行结果可以通过下面操作查看
找到容器的的进程id pid
进入容器网络命名空间并查看容器侧路由表
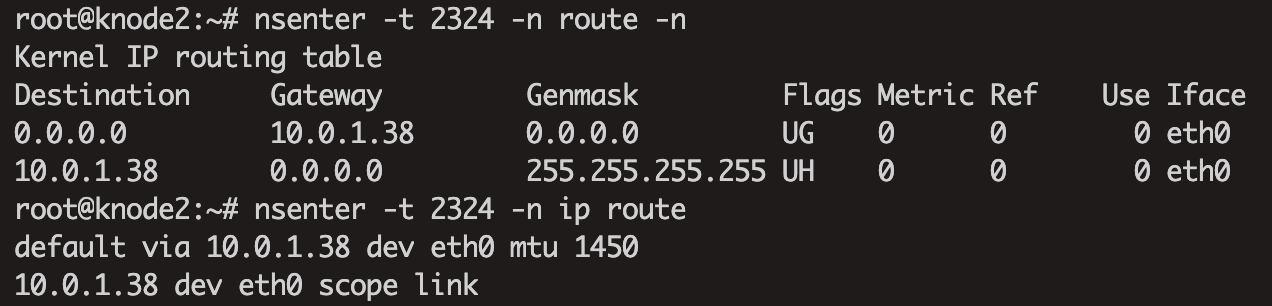
继续往下走
/opt/cni/bin/cilium-cni 二进制文件作为客户端调用 Cilium Agent Pod 服务端分配IP。• cilium-cni.go:427 -
ipam, err = c.IPAMAllocate("", podName, true)
[github.com/cilium/cilium/pkg/client]
• ipam.go:29 -
func (c *Client) IPAMAllocate(family, owner string, expiration bool) (*models.IPAMResponse, error)• ipam.go:42 -
resp, err := c.Ipam.PostIpam(params) [github.com/cilium/cilium/api/v1/client/ipam]
• ipam_client.go:85 -
func (a *Client) PostIpam(params *PostIpamParams) (*PostIpamCreated, error)服务端 ipam server ipam 模块逻辑 可看
主要逻辑还是通过本机 pod cidr 中分配出一个 pod ip
[github.com/cilium/cilium/daemon/cmd/ipam]
• ipam_client.go:85 -
[github.com/cilium/cilium/pkg/ipam]
• ipam.go:379 -
• ipam.go:111 -
通过一系列函数调用,会调用 hostScopeAllocator.AllocateNext() 来获取 pod ip
• hostscope.go:32 -
• hostscope.go:65 -
和上文说到 cilium 使用 k8s 源码中从 cluster cidr 划分多个 pod cidr 一样,cilium 也是复用了 k8s 源码中从 pod cidr 中划分出一个个 pod ip 的逻辑,cilium 为了防止引入其他 k8s 依赖包,单独把 k8s 源码中 ip allocator 逻辑 单独出来一个包 cilium/ipam 。
该包支持 pod ip 两种分配策略:随机顺序分配 randomScanStrategy 和连续顺序分配 contiguousScanStrategy,默认使用随机顺序分配(这种 IP 分配是DHCP服务端会根据POD的mac地址取哈希的方式去获取一个IP)。
总之,cilium cni 二进制作为客户端调用 cilium daemon 服务端 IPAM 模块,来从 pod cidr 中随机分配获取 pod ip,并在上文第一步中配置 pod 网卡。
0x03 eBPF
最后 cilium 对每个 pod 创建对应的 CiliumEndpoint 对象,在这一步会下发 tc eBPF 程序到 pod 网卡上
[github.com/cilium/cilium/plugins/cilium-cni]
• cilium-cni.go:526 -
c.EndpointCreate(ep)[github.com/cilium/cilium/pkg/client]
• endpoint.go:51 -
c.Endpoint.PutEndpointID(params)[github.com/cilium/cilium/api/v1/client/endpoint]
• endpoint_client.go:436 -
func (a *Client) PutEndpointID(params *PutEndpointIDParams) (*PutEndpointIDCreated, error)服务端
[github.com/cilium/cilium/api/v1/server/restapi]
• cilium_api_api.go:761 -
o.handlers["PUT"]["/endpoint/{id}"] = endpoint.NewPutEndpointID(o.context, o.EndpointPutEndpointIDHandler)[github.com/cilium/cilium/daemon/cmd]
• endpoint.go:532 -
func (h *putEndpointID) Handle(params PutEndpointIDParams) (resp middleware.Responder)• endpoint.go:308 -
func (d *Daemon) createEndpoint(ctx context.Context, owner regeneration.Owner, epTemplate *models.EndpointChangeRequest) (*endpoint.Endpoint, int, error)方法createEndpoint 先对 endpoint 的信息和 pod的注解进行了一些处理,然后创建 network policy ,这些地方先不关注, 重点关注 eBPF 程序的下发逻辑
• endpoint.go:500 -
ep.Regenerate(regenMetadata)有点不是很明白,
ep.Regenerate(regenMetadata) 是怎么调用到这里的,先继续往下走[github.com/cilium/cilium/pkg/endpoint]
• policy.go:315 -
func (e *Endpoint) regenerate(context *regenerationContext) (retErr error)这里需要注意下 ,context上下文赋值的路径,因为后面下发 bpf 程序的目录会用到,最终得到宿主机目录为 /var/run/cilium/state
• policy.go:368 -
origDir := e.StateDirectoryPath()• policy.go:369 -
context.datapathRegenerationContext.currentDir = origDir• policy.go:375 -
context.datapathRegenerationContext.nextDir = tmpDir其中
e.StateDirectoryPath() 获取逻辑为[github.com/cilium/cilium/daemon/cmd]
• daemon_main.go:1055 -
option.Config.StateDir = filepath.Join(option.Config.RunDir, defaults.StateDir) option.Config.RunDir-- github.com/cilium/cilium/pkg/option • config.go:2639
c.RunDir = viper.GetString(StateDir)- - github.com/cilium/cilium/daemon/cmd • daemon_main.go:702
flags.String(option.StateDir,defaults.RuntimePath, "Directory path to store runtime state") - github.com/cilium/cilium/pkg/defaults • defaults.go:41 -
RuntimePath ="/var/run/cilium"
defaults.StateDir- github.com/cilium/cilium/pkg/defaults • defaults.go:50StateDir ="state”
调用的入口为
[github.com/cilium/cilium/daemon]
• main.go:22 -
cmd.Execute()• policy.go:416 -
revision, stateDirComplete, err = e.regenerateBPF(context)regenerateBPF函数主要为重写 bpf headers
比如这样子
• bpf.go:595 -
headerfileChanged, err = e.runPreCompilationSteps(regenContext)如一行行向 ep_config.h 写入 C代码
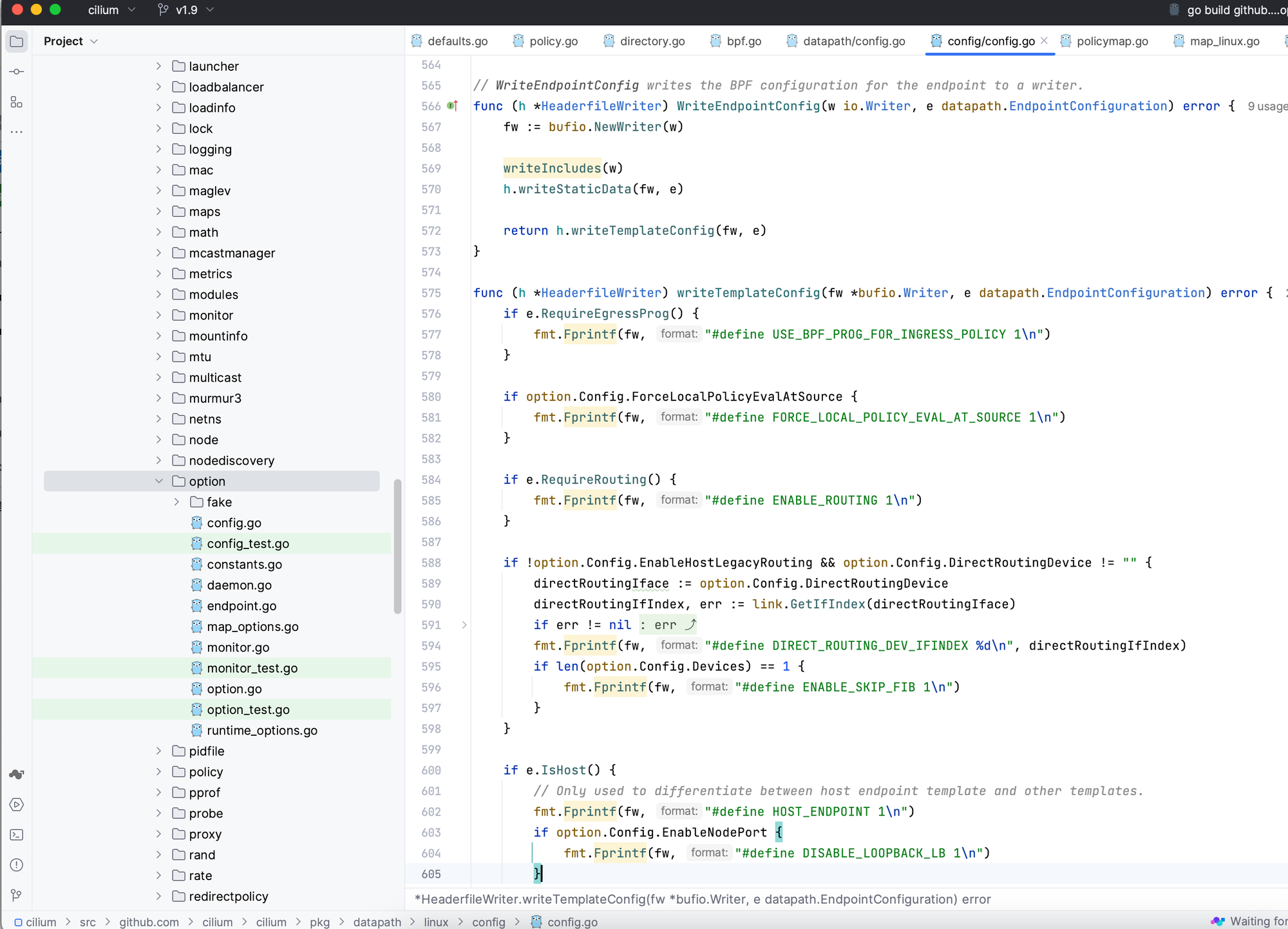
还有更新 bpf map 信息,下发到网卡中的bpf程序执行逻辑时会去获取bpf map数据
接下来就是编译和加载bpf程序
• bpf.go:624 -
compilationExecuted, err = e.realizeBPFState(regenContext)• bpf.go:705 -
e.owner.Datapath().Loader().CompileAndLoad(datapathRegenCtxt.completionCtx, datapathRegenCtxt.epInfoCache, &stats.datapathRealization)• loader.go:396 -
compileDatapath(ctx, dirs, ep.IsHost(), debug, ep.Logger(Subsystem))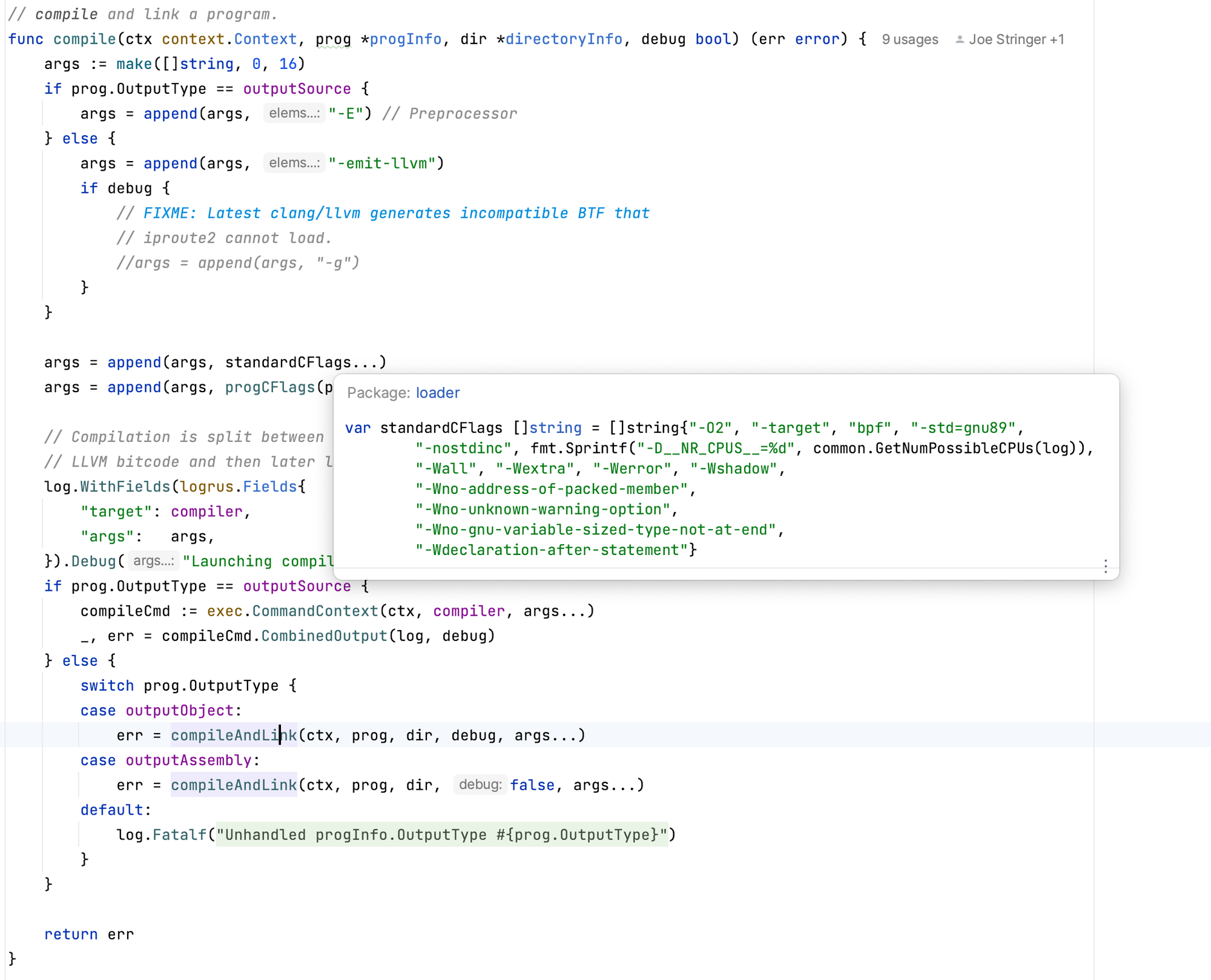
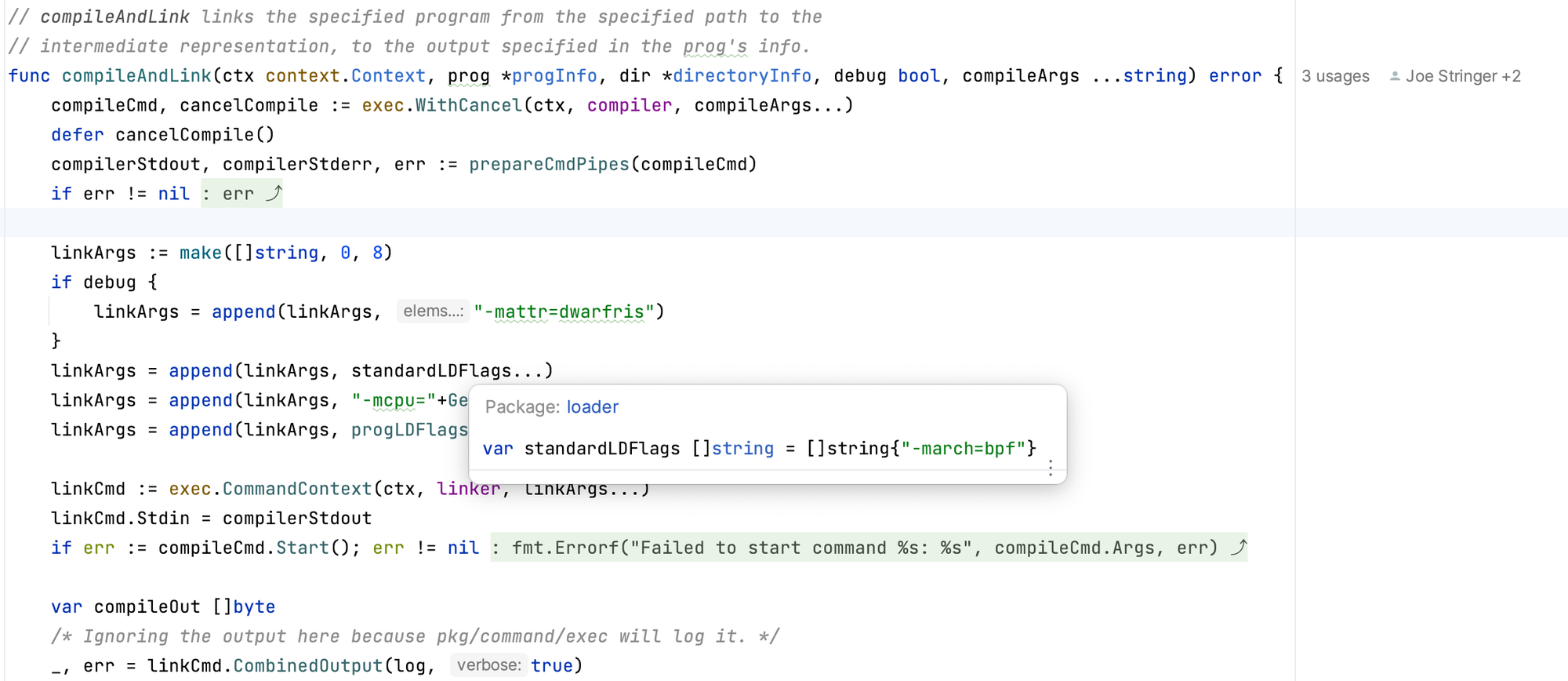
编译 bpf C 程序 Cilium 代码逻辑基本上就是执行类似如下命令
加载 bpf 程序
• loader.go:403 -
l.reloadDatapath(ctx, ep, dirs)• netlink.go:57 -
func (l *Loader) replaceDatapath(ctx context.Context, ifName, objPath, progSec, progDirection string) error
下发 bpf 程序到主机/POD网卡
以上代码逻辑已经编译并下发多个 BPF 程序到不同的网卡。可以通过如下命令查看:
假设容器中
ping clusterip-service-ip,出发走到另外一台机器的pod容器,会经过 from-container -> from-host -> to-netdev -> from-netdev -> to-host BPF 程序from-container BPF
[github.com/cilium/cilium/bpf]
• bpf_lxc.c:841 -
ipv4 则调用 tail_handle_ipv4 然后调用
• bpf_lxc.c:796 - handle_ipv4_from_lxc
函数主要完成:看看目标地址是否是 service ip,如果是则从 BPF Map 中找出一个 pod 作为目标地址,实现了 service 负载均衡
policy_can_egress4() 查看是否需要走 network policy,本文默认没有使用 network policy
ipv4_l3() 封包或者进行主机路由,设置 ttl 以及存储 src/dst mac 地址
from-container 经过 tc eBPF 后进入内核网络协议栈
上文介绍过容器内的路由网关是 cilium_host,packet 达到 cilium_host 网卡的 tc egress, 即走 from-host BPF 程序
调用 handle_netdev → do_netdev,这里的 identity,如果cilium使用默认 vxlan 模式,就是 vxlan id,通过 BPF map 维护
tail_handle_ipv4 → handle_ipv4 根据 目标 ipv4 查找 endpoint,即 pod ip
根据本机路由表,packet 会被转发给 eth0 网卡,会走 to-netdev BPF 程序
该 BPF 程序只会处理 NodePort service 或 主机防火墙的流量。本文暂不考虑 NodePort service packet。
经过以上 BPF 找到目标地址是另一台机器的 pod ip,包达到另一台机器,走 from-netdev BPF 程序,同样基本调用 from-netdev() 函数,逻辑和 from-host BPF 程序 基本一样,这里暂不赘述。
packet 到达 cilium_host 网卡走 to-host BPF 程序
调用
ctx_redirect_to_proxy_first → ctx_redirect_to_proxy_ingress4,把 packet 转发给 pod 网卡,这样可以跳过 Linux 内核协议栈 netfilter,性能更高0x05 Reference
[6] 云原生技术与架构实践年货小红书 P145 - P152 涉及 Kubernetes 容器网络模型和典型实现